みなさんこんにちは。サイボウズの三苫です。
本日は特にどこのイベントでも発表する予定もなく、実際に発表されなかった、不安定なテスト(Flaky Test)対策のお話をスライド & トークスクリプト形式で公開します。
不安定なテスト対策は、どこの現場でも継続的にされているかと思いますが私たちの一つの事例が皆様の対策の一助となれば幸いです。
さよなら Flaky 。不安定なテストの探し方

皆さんこんにちは。サイボウズの三苫と申します。本日は「さよなら Flaky 。不安定なテストの探し方」というお話をします。
私たちのお悩みごと

早速ですが私たちが抱えていた悩み、つまり前提となる課題からお話します。
サイボウズの kintone.com 基盤チーム(私の所属するチーム)はE2Eテストを使って AWS 上に構築した基盤上で kintone というサービスの動作保証をしようとしていました。
幸運にも kintone にはすでに多くのE2Eテストがあったからです。やったぞ、これが使えるぞと。
しかし実際にテストを流してみたところ、新しい基盤上では多くのE2Eテストが不安定になり基盤の不具合なのか単にテストが不安定なのか区別できずに困っていました。
これでは kintone の動作保証ができないぞと。
kintone というサービス

前置きなくお話をしていた kintone というサービスですが、こちらはサイボウズの業務改善プラットフォームという分野のクラウドサービスです。
国内データセンターで cybozu.com というドメイン、AWS の US リージョンで kintone.com というドメインで複数環境で提供しています。
それぞれの環境はかなり異なっており、データセンターだけではなく利用されるミドルウェアも別のものが使われています。ロゴも違いますね。

これがざっくりとした kintone の構成になります。
だいたいこんな感じで、kintone 本体のアプリケーションサーバーが複数のミドルウェアサービスやデータベースを利用しながら機能を提供するという感じになってるんですが…
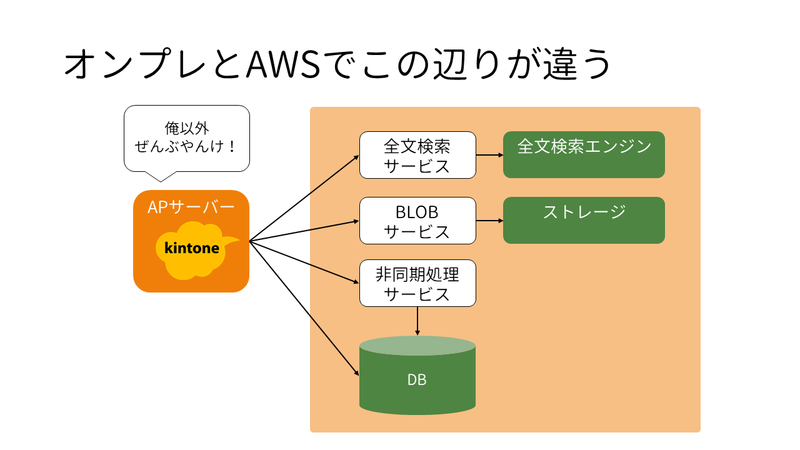
オンプレミス、つまり国内データセンターと AWS ではこの薄いオレンジ色で囲った部分が違うんですね。
ほとんどじゃないかと…

さらに、細かいことを言い出すとアプリケーションサーバーもオンプレミスでは VM 上で動作しているんですが、AWSでは Docker コンテナとして動いているので、まぁかなりの部分が違います。
この二つは本当に同じ動作?

さて、そうなると気になるのがこの二つは本当に同じ動作なのかというところです。
中身が全然違うので不安になってきますよね。
どうやってこの二つの環境で同じ動作であることを保証したらいいでしょうか?
同じE2Eテストで外形的にテストします

同じE2Eテストで外形的にテストすればよいでしょう。
そうすれば、少なくとも外から見える動作的には同じですというところまでは言えます。
E2Eテスト

ここまで、特に説明なくE2Eテストという用語を使ってきました。これはどういうテストでしょうか。
スライドではE2Eと表記していましたが、エンドツーエンド、つまり利用サイドから実際に処理をするサーバーサイドまで、端から端まで、ある部分だけをテストするのではなく全体をテストするという事です。
実際に動く環境を用意しユースケースの一連のシナリオを達成できるか検証します。
Webアプリケーションであればブラウザ操作を自動化してテストすることが多いかと思います。kintone では Selenium を使っています。

E2Eテストの良いところ、悪いところ、どんなものがあるでしょう。まずは良いところから。
エンドユーザーの利用と同じ方法でテストできます。Webアプリケーションであればブラウザを使って動作を検証できます。
そして、内部のコンポーネントの状態はブラウザからは確認できませんので、純粋にユーザーから見た外部仕様をテストすることができます。
また、実際に動く環境を用意することになるので、各コンポーネントをすべて結合してユースケースが達成できるかどうか、その結合をテストすることができます。
一方、悪いところです。
実際に動く環境を用意することは良い点もあるのですが、セットアップや実行に時間がかかることになります。
これは自動化されていても環境一式用意するとなると VM などのセットアップなども含めるとそれだけで数分のオーバーヘッドがかかってしまいます。
また、ブラウザの挙動やネットワークなどテストケースで十分に制御しきれない要素が出てくるのでテストが不安定になりがちです。
こういうものを俗に Flaky Test と呼ぶそうです。はがれやすい、もろいテストという事ですね。
このようなテストは最終的にデバッグ体験が最悪になりますので、問題が起きた時に修正するのがかなり厳しいという事になります。
テストが不安定だと何がまずいか

良いところ、悪いところをお話しましたが、そもそもテストが不安定だと何がまずいでしょう?
まず、テスト全体の信頼性が失われてしまいます。成功するまでテストを再実行するとかですね。
「先輩、テストが落ちるんですが?」
「信心が足りないね。心を込めて再実行しなさい」
など神がかった現場、皆様に覚えはないでしょうか。
次に、テストの成否そのものが次第に無視されるようになります。このテストは失敗しても気にしなくていいよ、とか甘い言葉に誘われて次第にテストの結果を気にしなくなります。
不安定だからと修正しても、直ったのか偶然テストがパスしたのか区別できなくなります。10回パスしたから大丈夫だろと思っても、大丈夫じゃなかったりします。
ここまでは単にテストだけの問題なのですが、テスト全体の信頼性が損なわれることにより潜在的な不具合が見過ごされてしまうという事が起きてしまいます。
たまに失敗するテストケースがロジックのコーナーケースを踏んでたりする場合もありますね。日曜日だけ落ちるとか、月初だけ落ちるとか。
こういう、検出できていたものを見過ごしてしまうと非常によろしくないです。
不安定なテストの探し方

テストが不安定だとまずい事がわかりました。では、不安定なテストをどうやって探しましょう。これがなかなか難しい。
なぜかというと、一回のテスト結果だけでを不安定かどうかを判断できないからですね。一回のテスト結果は成功か失敗かのどちらかです。複数回の結果を見て不安定かどうかを判断する必要があります。
例えば、あるテストケースがコミットごとに実行されるとして 5 回のテスト結果を見るとしましょう。
この時、例えば失敗の回数に着目するとどちらも 5 回中 3 回失敗しています。
ですが Case1 のように、2回連続して成功し、その後3回失敗しているという場合は不安定というよりもどこかで失敗するテストになったと考えられます。
ここで、変化に着目すると Case2 では、5回中3回失敗という意味では Case1 と同じですが、テスト結果が変わりうるタイミング4回のうち4回。すべてで変わっています。こちらは不安定になったのではないかと考えられます。
このように、同一ケースの複数のテスト結果を時系列で並べてみると不安定かどうかがわかりやすいですね。
テストの実行履歴とか残してます?

これで不安定なテストの探し方がわかりました。探し方がわかりましたがどうやって私たちの現場で調べましょう。テストの実行履歴を残して、今言った指標を簡単に参照できるようになってるでしょうか。
代表的な CI / CD ツールである Jenkins や CircleCI の実行履歴の場合、ビルドごとにテスト結果を見る必要があります。 あるテストケースの傾向という軸でみるための UI がないんですね。もしかしたらプラグインなど工夫すれば見られるかもしれませんが、すみません、そこは私も不勉強なのでわかっていません。
不安定なテストケースの場合、テストケースごとの成功・失敗の頻度を見る必要があります。そして、失敗した時は不安定になった原因は様々ですのでその場でログを見て確認できるようになっていて欲しいです。
さて、そういう要件にピッタリ合うようなプロダクトやソリューションはあるでしょうか。
ReportPortal

私たちのチームは ReportPortal というソフトウェアを利用しています。
これは、自動テストの結果を記録してダッシュボードを作るためのソフトウェアで、テスト結果を様々な軸から分析することができます。
CI やローカルでテストの実行して生成される JUnit XML 形式の結果をテスト実行中や完了後に ReportPortal に送信して一覧・分析することができます。
また、多数のテストフレームワークとのインテグレーションにも対応しています。
他にも機械学習とか便利な機能も多くあるようですが、私たちはまだ単純なレポーティングの用途でしか使用していません。
不安定なテストの分析

さて、実際に ReportPortal を利用した例を見てみましょう。
これは kintone に存在するE2Eテストで不安定なテストや失敗の多いテストをレポートしたものです。
ここで API というのは kintone のサーバーが提供している API を JUnit テストケースから呼び出してテストするテストスイートで、UI というのはブラウザを用いたテストのテストスイートになります。これをそれぞれランキング形式で表にしています。
テストケース名などは出せないのでモザイクになってしまっていますが、どのようなテストケースが不安定か、たくさん落ちているかがわかります。
このようにランキング形式で出すことで不安定の原因になっているテストを効率的に修正することができますので、E2Eテストの信頼性を高めていくことができます。
テストの実行履歴

次に問題を修正するためにあるテストケースの詳細を見る画面です。 修正に取り掛かる際、そのテストケースの失敗の傾向やログを把握したくなるかと思います。 この例ではビルド #1321 から失敗し始めていて、その前のビルド #1320 でも実行時間が伸びているのがわかりますね。 時計マークの +1719% というのが実行時間が伸びているということです。 また、テスト実行時のログも下の画面、こちらもモザイクかけてしまっているのですが参照する事ができます。
この辺りの情報を合わせてみると原因が特定しやすくなってきます。
私たちのビフォー・アフター

ReportPortal を導入した私たちのビフォー・アフターです。
ビフォーでは、経験をもとにテストが不安定かどうか判定して再実行や修正を行っていました。 詳細なテスト結果はログから追う必要があるので必要になるまで確認しない、腰が重い状態でした。
アフターでは、不安定なテストを実績をもとに判断できるようになりました。 これによって、明らかなバグか不安定で落ちやすいかの区別がつくようになり、修正する効果の大きなテストから修正していけるようになりました。
まとめ

それでは、本日のお話のまとめです。
E2Eテストは不安定になりやすく特定したりデバッグしにくいという課題を、私たちの事例をもとにお話しました。
不安定なテストを探すには、テストの実行履歴を用いて分析すると特定しやすくなります。
そして、最後に私たちが不安定なテスト探しに活用している ReportPortal というツールの紹介を行いました。
おしまい

以上、「さよなら Flaky 。不安定なテストの探し方」というお話でした。 最後までお読みいただきありがとうございました。
私たちのチームは DevOpsエンジニア(AWS版kintone) としてキャリア採用を募集しています。ご興味ある方はご参照ください。