はじめに
Cloud Platform部のpddgです。2024年もサマーインターンシップを開催し、プラットフォーム(自社基盤)コースとして2名の方を受け入れました。 昨年の様子は以下からご覧いただけます。興味があれば是非ご覧下さい。
今回は受け入れたお二方のうち藤本陽人さん(static-fuji)に担当していただいた検証の中で発見したやや直感的でない挙動について、藤本さんによる検証結果を社員がまとめたものになります。 この記事内での検証のほとんどはインターン生である藤本さんによって実施されたものですが、一部社員がインターンシップ完了後にこの記事の執筆のために生成した図等も含まれます。
また、もう一人のインターン生の方にはRustでロードバランサを書くという課題に挑戦していただきました。こちらもインターン生の方に大活躍していただいています。是非ご覧下さい。 blog.cybozu.io
背景
サイボウズでは、現行のインフラ基盤上で動作しているアプリケーション・ミドルウェアをKubernetesベースの新基盤に移行するプロジェクトを推進中です。 その中で、課題の一つとしていわゆる静的コンテンツ(JavaScript・CSSなど)の配信サービスが挙げられています。現在はnginxを利用して配信しており、そのホストのローカルファイルシステム上に静的コンテンツをアップロードしています。 この方式はnginxによって安定して高速にレスポンスを返せるのですが、コンテンツ配信サーバがステートフルになってしまい、Kubernetesとの相性が良くないという問題があります。
そこで、新基盤ではCephのObject Storageを活用し、アプリケーションチームが持つS3互換のオブジェクトバケットに静的コンテンツをアップロードし、そこからnginxが取得・キャッシュして配信するサービスを検討していました。これによりnginx自体はどのバケットを見に行くかのみ知っていればよく、nginxコンテナ自体はステートレスにできます。
PoCを作成し実際に動作することはわかったものの、その性能(レイテンシ・スループット、ローリングアップデート中のパフォーマンスや、バックエンドのバケットへどれくらいのアクセスが発生するか等)を検証するために、インターン生としてジョインした藤本さんへ検証を依頼しました。
nginxの設定
このPoCにおいてnginxには以下の様な設定を施しています。ただし、直接的に関係がありそうなところだけ抜粋しており、他の設定は省略しています。
load_module /usr/lib/nginx/modules/ndk_http_module.so; http { # proxy cacheの設定 proxy_cache_path /cache/contents levels=2 # 実際に使われている静的コンテンツのサイズを見て決めた値 keys_zone=cache:32M max_size=8G inactive=24h ; # proxy_cache_path と同じデバイス上のディレクトリを指定する proxy_temp_path /cache/temp; # 静的コンテンツを配信するupstream upstream origin { # ここには実際の値が入る server {{ORIGIN_HOST}}:{{ORIGIN_PORT}} max_fails=0; keepalive 16; } server { listen 8080; proxy_cache cache; # キャッシュのキーはURLとする。 # GET と HEAD を同一視したいので $request_method は使わない。 # また、クエリ引数は無視する。 proxy_cache_key "$scheme://$host$uri"; # 200 OK, 301 Moved Permanently, 302 Found, 303 See Other は1ヶ月キャッシュする proxy_cache_valid 200 301 302 303 2592000s; # それ以外のパターン (400, 429, 500 など) # オリジンサーバーを守るため一瞬だけキャッシュする。 proxy_cache_valid any 1s; # キャッシュの更新中に同じ URL に対する問い合わせをブロックすることで、 # オリジンサーバーへの問い合わせを減らす。 proxy_cache_lock on; # proxy_pass にはエスケープ済みのパスを渡す必要がある。 # しかし、$uri は unescape されているため、Lua を使ってエスケープしなければならない。 # # Q. なぜ $request_uri を使わないのか? # $request_uri は入力されたパスがそのまま入っているため、エスケープ済みのはずである。 # A. 例えば、$request_uri が "/../secretbucket/foobar" だった場合、不正に他のバケットにアクセスされてしまう。 # 一方 $uri は正規化済みであるため /../ のような邪悪な文字列を含まない。 set_by_lua_block $escaped_path { -- ngx.escape_uri は JavaScript の encodeURIComponent と等価な関数である。 -- しかし、ここでは JavaScript の encodeURI 相当の関数が必要なので自作する必要がある。 -- (最新の lua-nginx-module にはそのような関数が存在するが、apt で入る lua-nginx-module は残念ながら古い) -- https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/encodeURI local function encode_uri(uri) return uri:gsub("[^A-Za-z0-9;,/?:@&=+$_.!~*'()#-]", function(c) return string.format("%%%02X", string.byte(c)) end) end return encode_uri(ngx.var.uri) } location / { # ここには実際の値が入る proxy_pass http://origin/{{BUCKET}}$escaped_path; } }
負荷試験の実施
Grafana k6を利用して負荷試験を実施していただきました。負荷試験の構成は以下の通りです。
- テスト時間: 60s
- 1秒あたりのリクエスト数(rate): 100~10000回(後述の表の通り)
- テスト回数: リクエスト数ごとに1回
- 確認するデータ: レイテンシの平均(avg)、最小値(min)、中央値(med)、最大値(max)、パーセンタイル(p(90)、p(95))
- リクエストの送信を行うPodのリソース
- CPU: 18 core
- メモリ: 24GiB
- Nginx Podのリソース
- 3レプリカ
- CPU: 4 core
- メモリ: 18GiB
テスト実行ごとにNginxのPodは再作成し、キャッシュは揮発させて試験しています。また、Cephの構成やスペックなどは複雑であること、本記事の現象と直接関係しないことから省略させてください。
アクセスする対象のファイルは以下のスクリプトで作成された10000個のテキストファイルで、予め対象のバケットにアップロードしてあります。
output_dir="./static-contents" num_files=10000 num_chars=10000 mkdir -p "$output_dir" for i in $(seq -f "%05g" 1 $num_files) do filename="file_$i.txt" base64 /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c $num_chars > "$output_dir/$filename" done
また、k6のスクリプトは以下の通りです。
import http from 'k6/http'; import { check } from 'k6'; // ランダムにアクセスするため既存のモジュールを利用 // Ref: https://grafana.com/docs/k6/latest/javascript-api/jslib/utils/randomitem/ import { randomItem } from '/tmp/index.js' // 対象のSericeのアドレス const baseUrl = 'http://nginx.dev-static-poc.svc.cluster.local/'; const fileNames = Array.from({ length: 10000}, (_, i)=>`file_${String(i).padStart(5, '0')}.txt`); // file名は"file_0XXXX.txt" となっている(Xには0~9の整数が入る) export const options = { scenarios: { contacts: { executor: 'constant-arrival-rate', duration: '60s', timeUnit: '1s', preAllocatedVUs: 200, // 実験の条件ごとに変動 rate: 10000, }, }, }; export default function (){ const params = { timeout: '10s', }; const fileName = randomItem(fileNames); const url = `${baseUrl}/${fileName}`; const res = http.get(url, params); // レスポンスが返ってきて200であることを確認 check (res, {'status = 200': (r) => r.status === 200}); }
測定結果
今回設定した範囲の秒間リクエスト数ではほとんどのケースで十分高速に応答できていましたが、どのリクエスト数の場合でも最も遅いケースでは500msあたりでレイテンシが頭打ちする傾向があることがわかりました。タイムアウトなどの設定を疑いましたが、正しくStatus Code 200が返ってきていました。
| rate | avg (μs) | min (μs) | med (μs) | max (ms) | p(90) (ms) | p(95) (ms) |
|---|---|---|---|---|---|---|
| 100 | 14,040 | 285.41 | 7,300 | 500.45 | 29.17 | 43.77 |
| 500 | 3,450 | 230.08 | 1,570 | 499.71 | 2.54 | 14.41 |
| 1,000 | 2,220 | 212.39 | 394.25 | 500.64 | 1.95 | 3.87 |
| 10,000 | 950.15 | 173.91 | 269.17 | 507.99 | 0.42 | 1.43 |
以下は出力されたnginxのログ中のレスポンスタイムから、ステータスコード別に最大値を時系列でプロットしたものです。縦軸が秒、横軸は経過時間を表します。全て200が返っており、最初の数秒は500ms程度のレイテンシが観測され、その後はほぼ0に近づいていました*1。

この結果から、upstreamであるオブジェクトストレージからデータを取得している間にだけ500ms程度の待ち時間が発生する場合があると推測しました。その後今回の試験に含まれうるデータ全てのキャッシュが完了すると、nginxは非常に高速にレスポンスを返すようになりこのような結果になったのではないかと考えました。
当初これはupstreamであるCephのオブジェクトストレージの性能になんらかの特性があり、このようなレイテンシが発生するケースが多いのかと考え、Cephのオブジェクトストレージが公開するエンドポイントに直接リクエストする負荷試験を行ってみました。
| rate | avg (μs) | min (μs) | med (μs) | max (ms) | p(90) (ms) | p(95) (ms) |
|---|---|---|---|---|---|---|
| 100 | 4,230 | 1,010 | 1,640 | 245.91 | 2.94 | 16.07 |
| 500 | 3,870 | 848.89 | 1,390 | 217.74 | 2.54 | 14.41 |
| 1,000 | 4450 | 826.12 | 1,350 | 279.08 | 7.17 | 20.03 |
| 10,000 | 19,960 | 813.8 | 17,830 | 342.66 | 32.53 | 40.17 |
しかし、結果として実測したレイテンシは最大でも500msまで達することはありませんでした。nginxからはproxy_cache_lockによってCephへのリクエスト数はこの負荷検証よりも少ないことを考えると、Cephがリクエストを捌ききれなくなっているといった問題も考えにくいと判断しました。
ここまででおそらくnginxに問題があるであろうことが分かったため、リソース量などの調整をしたりしましたが、問題は解消しませんでした。ソースコードに目を通したときproxy_cache_lockの実装に問題がありそうに思えたのでこの設定を外してみたところ、問題が解消する様子が観測され、最大でもcephのオブジェクトストレージからのレスポンスタイムに近いレイテンシで収まるようになりました。
| rate | avg (μs) | min (μs) | med (μs) | max (ms) | p(90) (ms) | p(95) (ms) |
|---|---|---|---|---|---|---|
| 100 | 6,970 | 225.36 | 1,690 | 254.06 | 19.43 | 30.85 |
| 500 | 5,970 | 216.04 | 1,640 | 293.99 | 17.88 | 27.02 |
| 1,000 | 2,870 | 193.73 | 395.05 | 246.27 | 2.35 | 10.4 |
| 10,000 | 656.6 | 169.22 | 265.43 | 224.46 | 0.42 | 1.4 |
我々の想定していた挙動
測定された結果は我々の想定とは異なるもので、実装時にはnginxのproxy_cache_lockはGoにおけるsingleflightのような挙動をすると想定していました。
つまり、同じキーに対して複数のリクエストが来た場合、最初のリクエストがupstreamに問い合わせを行い、その結果をキャッシュに保存し、他のリクエストはその結果を待ってキャッシュから取得するというものです。これにより並列リクエストが来た場合にupstreamへの問い合わせが1回になるため、upstreamへの負荷を抑えられ、レスポンスの遅延も最大でupstreamへの最初の問い合わせのレイテンシぶんになると考えていました。
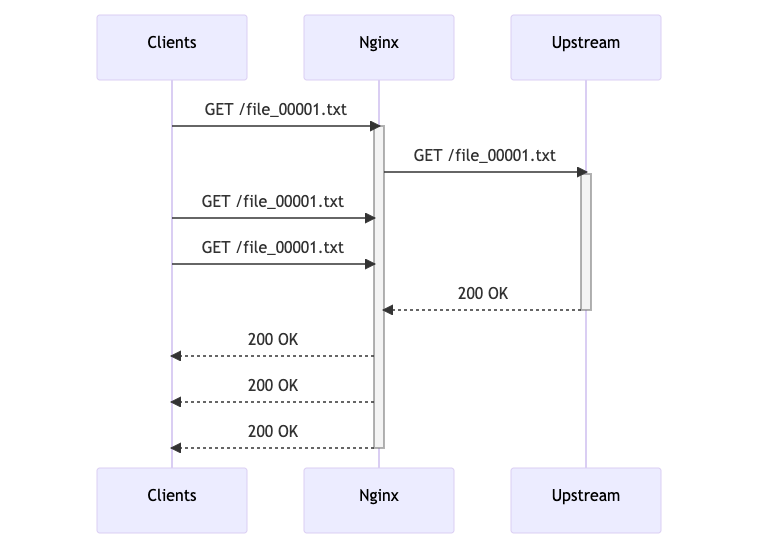
しかし、測定結果からproxy_cache_lockの挙動は我々の想定していたものとは異なる可能性が高いことがわかりました。
なぜ500msで頭打ちするのか
怪しいと睨んだproxy_cache_lockの実装には、以下のようなコードがありました。 https://github.com/nginx/nginx/blob/fb89d50eeb19d42d83144ff76c80d20e80c41aca/src/http/ngx_http_file_cache.c#L404-L460
一部を抜粋します。
timer = c->wait_time - now;
ngx_add_timer(&c->wait_event, (timer > 500) ? 500 : timer);
なんかここに500msくらいで発火しそうなタイマーの実装が入っているように見えますね……
https://nginx.org/en/docs/dev/development_guide.html#timer_events
The function ngx_add_timer(ev, timer) sets a timeout for an event, ngx_del_timer(ev) deletes a previously set timeout. The global timeout red-black tree ngx_event_timer_rbtree stores all timeouts currently set. The key in the tree is of type ngx_msec_t and is the time when the event occurs. The tree structure enables fast insertion and deletion operations, as well as access to the nearest timeouts, which nginx uses to find out how long to wait for I/O events and for expiring timeout events.
nginxの開発ドキュメントにもこの ngx_add_timer は指定された時間でタイムアウトし何らかの処理を行う関数であると書かれています。proxy_cache_lockの実装では wait_time - now と 500 のうち小さい方をタイマーにセットしているため、500msでタイムアウトして処理が発火するようです。
wait_timeを設定しているのは実は0で初期化されるときを除いて以下の箇所だけであり、実際のところlock_timeoutの秒数でtimerの設定値が変わり、最大500msのタイマーになっていることがわかります。
if (c->wait_time == 0) { c->wait_time = now + c->lock_timeout; c->wait_event.handler = ngx_http_file_cache_lock_wait_handler; c->wait_event.data = r; c->wait_event.log = r->connection->log; } timer = c->wait_time - now;
このlock_timeoutはproxy_cache_lock_timeoutの値を参照しておりデフォルトでは5秒になっています。
https://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_cache_lock_timeout
よって、proxy_cache_lock_timeoutをデフォルトのままproxy_cache_lockを有効にすると、リクエストは500msごとにロックの状態を確認してレスポンスを返すようになっていることがわかりました。upstreamがこれよりも短い時間で応答を返したとしてもこの時間で律速されてしまうため、最大で500msのレイテンシが発生することがわかりました。
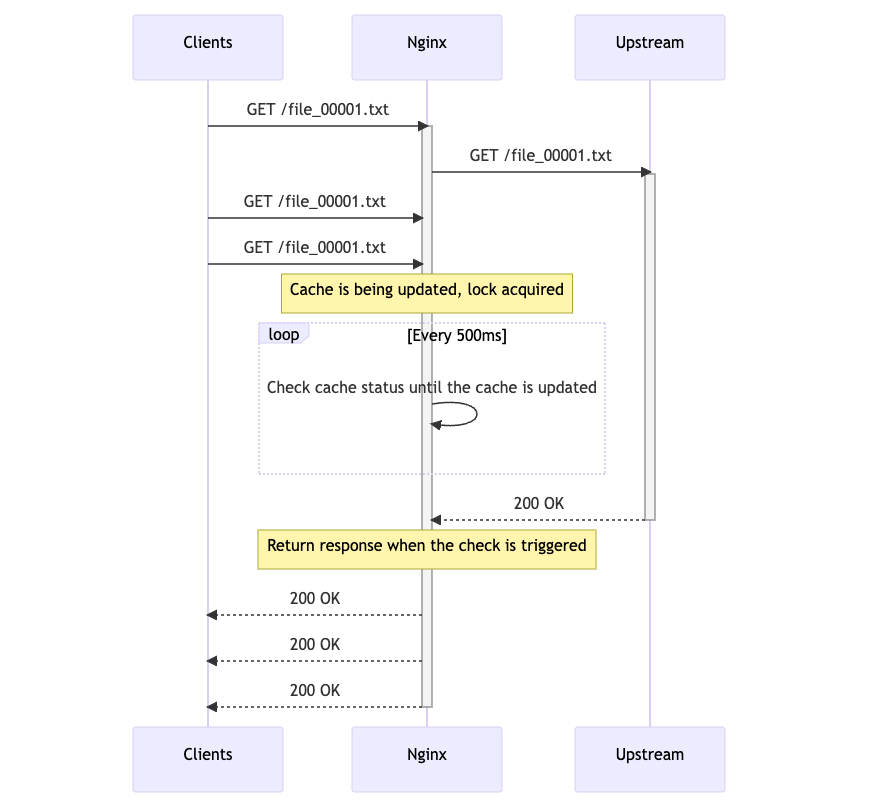
対策
対策と言えるほどのものではありませんが、upstreamのレイテンシが500msよりも小さいことが分かっているとき proxy_cache_lock_timeout を500msよりも小さい値にすることで、最大のレイテンシを下げることができました。
例えば400msにしてみた結果が以下の通りです。
| rate | avg (μs) | min (μs) | med (μs) | max (ms) | p(90) (ms) | p(95) (ms) |
|---|---|---|---|---|---|---|
| 100 | 8,490 | 279.88 | 2,200 | 230.38 | 22.63 | 28.75 |
| 500 | 3,430 | 221.32 | 1,600 | 585.7 | 4.19 | 16.96 |
| 1,000 | 1,720 | 192.38 | 390.72 | 400.16 | 1.9 | 2.65 |
| 10,000 | 635.45 | 163.52 | 262.52 | 401.94 | 0.42 | 1.4 |
lock_timeoutを400msに設定すると、500msではなく400msのところにレイテンシの壁が生まれるようになりました。

ただしこれはupstreamへ送られるリクエスト数とのトレードオフの関係にあるため、無制限に短くすることはできません。このタイムアウト時間を超えたとき、そのリクエストはそのままupstreamに送られ結果はキャッシュされないとproxy_cache_lock_timeoutのドキュメントには記載されています。そのためupstreamに期待される速度よりも短いタイムアウトを設定してしまうと、その時間内に応答が返らないためupstreamへのリクエスト数が増え、結果としてupstreamへの負荷が増えることになります。
まとめ
インターンシップを開催し学生である藤本さんに我々が検討した静的コンテンツ配信システムのPoCの負荷検証を行っていただきました。メンターが想定していなかったところにパフォーマンス上の問題が存在し、さらにそれがnginxの仕様であることを明らかにしていただきました。大変助かりました。ありがとうございました。
今後はこのような問題が発生することを念頭に、どのように静的コンテンツ配信システムを構築するかメンターは頭を抱えています。このような問題の解決に一緒に取り組んでいただける仲間を募集しています。ご興味があれば是非サイボウズの採用情報をご覧ください。
【更新履歴】2024/10/01 もう1人のインターン生の活躍を紹介する記事のリンクを、追加しました。
*1:これはnginxのログの精度がミリ秒までであり、マイクロ秒で返っている応答はログ上では0になってしまうためです。表のデータはクライアント(つまりk6)の出力するデータを元にした値のためマイクロ秒まで出力されています。