
この記事は、CYBOZU SUMMER BLOG FES '25の記事です。
こんにちは、25新卒フロントエンドエンジニアのmehm8128(めふも)です。
サイボウズでは現在、フロントエンド刷新プロジェクトとしてkintoneをGoogle Closure ToolsというフレームワークからReactに移行しています。詳しくは以下の記事をご覧ください。
僕はその中でも、kintoneのアプリに関連する画面のReact化を行っている、「ババロア」チームに所属しています。
アプリではレコードを作成でき、以下のようにレコードの情報を編集したり閲覧したりできます。

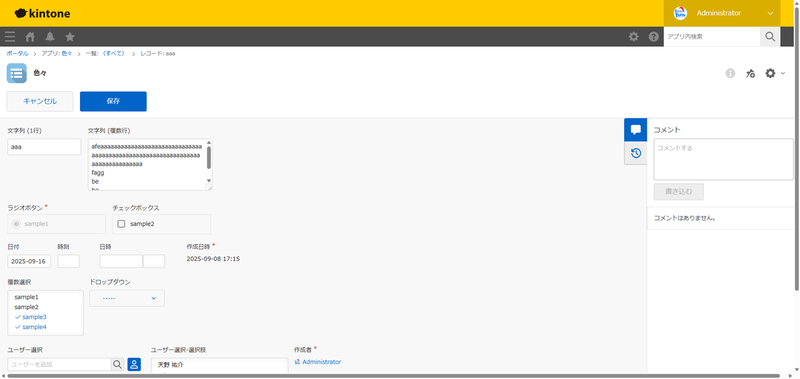
この記事では、ババロアチームでReact化を行うにあたり実装していたインテグレーションテスト(以下integテスト)の書き方を改善したケースを例にとり、kintoneアプリ領域のフロントエンド刷新について紹介します。
kintoneアプリ領域で扱う巨大データ
kintoneのアプリ領域では前述のように、アプリごとに設定されているフォームに情報を入力し、それを閲覧・編集できるようになっています。
フォーム情報には、各フィールドの種類やそのフィールドに対する設定情報、どのフィールドがどの位置に配置されるのかという情報が含まれています。これらを全て扱う都合で、かなり巨大なデータを扱わなければなりません。
具体的に、バックエンドから取得できるデータの例を紹介します。
フォームスキーマ
getFormSchemaという関数で、バックエンドからフォームのスキーマを取得することができます。これは、以下のような形式になっています。
vi.spyOn(cybozuData, 'getFormSchema').mockReturnValue({ groups: [], table: { fieldList: { '2000': { id: '2000', label: '文字列(1行)', var: '文字列__1行_', type: 'SINGLE_LINE_TEXT', properties: { noLabel: 'false', required: 'false', defaultValue: '', expression: '', hideExpression: 'false', max: null, min: null, unique: 'false' } }, ...(同様に他のフィールドが羅列される) } } });
fieldListの中に各フィールドのデータが羅列されています。これはフィールドの分だけ詰め込まれていて、kintoneのフォームでは約30種類ものフィールドを配置することができるため、全種類のフィールドを配置するとこれ1つで巨大なデータになります。
フォームレイアウト
同様に、getFormLayoutという関数でフォームのレイアウト情報を取得することができます。これは、以下のような形式になっています。
vi.spyOn(cybozuData, 'getFormLayout').mockReturnValue([ { id: null, type: 'ROW', isSubTable: false, label: null, var: null, controlList: [ { type: 'SINGLE_LINE_TEXT', label: '文字列(1行)', var: '文字列__1行_', styleMap: { width: 193 } }, ...(同様に他のフィールドが羅列される) ] } ]);
先ほどのスキーマ情報ほど多くないものの、こちらもアプリに配置されているフィールドの分だけ情報が詰め込まれているため、巨大なデータになりがちです。
レコードのデータ
上記2つのデータはアプリの設定情報でしたが、こちらは実際にアプリに登録されるレコードのデータです。
こちらもコメントで書いているように、フィールドの数だけデータ量が増える部分があり、設定情報のデータと同様に巨大になりがちです。
今回の例では最小構成ですが、プロセス管理機能が有効化されていたり、関連レコード一覧やフィールドルックアップ、サブテーブルなどといった特殊なフィールドが利用されていたりするとそれらの情報が含まれ、さらに大きくなります。
vi.spyOn(getWithAcl, 'getWithAcl').mockResolvedValue({ record: { record: { id: "1", revision: "1", state: null, table: { id: "1", row: [ { id: "100", rowOrder: 0, change: null, fieldList: { "2000": { id: "2000", type: "RECORD_ID", change: null, value: { value: "1", }, values: null, errors: null, error: null, }, ...(同様に他のフィールドが羅列される) }, }, ], }, subTable: { "2": { id: "2", row: [], }, ...(同様に他のフィールドが羅列される) }, lookups: [], referenceTableMasters: [], title: "app", comments: null, fieldAccessibility: { "2000": "READ", ...(同様に他のフィールドが羅列される) }, }, actions: null, referenceTableError: null, }, actions: [], viewable: true, editable: true, deletable: true, referenceTableError: null, });
ババロアにおけるintegテストと、地獄のintegテスト
ババロアでは機能ごとにQAエンジニアの方が作成したテストケースを基に、VitestとReact Testing Libraryでintegテストを書きます。
integテストでは毎回、テストしたいアプリの設定・レコードデータになるように、主に前述の3つのレスポンスをモックしています。
それぞれフィールドの数だけデータが大きくなるため、1つフィールドの追加するたびに3つのモックでそれぞれコードが増えます。
さらに、モックするデータ間でフィールドのidなどの整合性を取らなければ上手く動いてくれないことが辛いポイントの1つです。例えばformSchemaにある文字列(1行)フィールドの情報とformLayoutにある文字列(1行)フィールドの情報で、idが異なる場合に画面に上手くフィールドを表示することができないのです。
巨大データを扱う上で辛いところは色々ありますが、今回はこのintegテスト実装に絞って紹介していきます。
巨大データについてのもう少し詳細なデータ構造の話や、条件分岐の実装における辛さについては同じババロアチームのメンバーの登壇スライドをご覧ください。
具体的にintegテストを1つ紹介します。707行のintegテストの例です。
ドメイン知識が必要な部分でもあるので、なんとなく理解してもらえばOKです。
今回のテストは、JSAPI(ブラウザ上でJavaScriptから実行できるkintoneのAPI)の実装に関連するテストです。具体的にはapp.record.create.change.[フィールドコード]イベントが発生し、イベントオブジェクトでフィールドの編集可/不可を設定されたときに、ちゃんとフィールドの編集可/不可が変化するかどうかを確認します。
それを計18フィールドで確認していて、テストファイルで実行するJSAPIは以下のようになっていました。
kintone.events.on(`app.record.create.change.${fieldCode}`, (event) => { const record = event.record; record['文字列1行2'].disabled = disabled; record['文字列複数行'].disabled = disabled; record['数値'].disabled = disabled; record['リンク'].disabled = disabled; record['ラジオボタン'].disabled = disabled; ...(同様に他のフィールドに対してdisabledにする処理が羅列される) return event; });
そして、これら18フィールドに対して画面からフィールドを取得する処理と、フィールドの編集可/不可を確認する処理があります。
const inputTargetSingleLineText = screen.getByRole('textbox', { name: '文字列1行1' }); const singleLineText = screen.getByRole('textbox', { name: '文字列1行2' }); const multipleLineText = screen.getByRole('textbox', { name: '文字列複数行' }); const decimal = screen.getByRole('textbox', { name: '数値' }); const link = screen.getByRole('textbox', { name: 'リンク' }); const radioButton = screen.getByRole('radio', { name: 'オプション1' }); ...(同様に他のフィールドの取得処理が羅列される)
expect(singleLineText).toBeDisabled(); expect(multipleLineText).toBeDisabled(); expect(decimal).toBeDisabled(); expect(link).toBeDisabled(); expect(radioButton).toBeDisabled(); ...(同様に他のフィールドのexpectが羅列される)
実際にはフィールドを表示するためにformSchemaやformLayout以外にも色々とモックする必要があります。そのため、実際にはモックだけでさらに膨れ上がります。
このように、これまでのintegテストは書くのがかなり辛くなっていました。

そこで、スプリントの振り返りで議論し、モックヘルパー関数を導入することにしました。
テストのモック処理にロジックが入ることによる懸念や将来的な技術的負債に繋がる可能性もありますが、今回の場合はそれらよりもモックヘルパーを導入することによるinteg実装の効率化のメリットの方が大きいということから、調査・導入が決まりました。
モックヘルパー関数の導入
地獄のintegについて説明したところで、それをどのように解決したのかを説明していきます。
従来はformSchemaやformLayoutなどを宣言的に構築したものをvi.spyOn()に突っ込んでいました。しかし今回はそうではなく、追加したいフィールドを命令的に追加していくようなI/Fにしました。
具体的には、主に以下のような流れでモックできるようにする方針を立てました。
- フォームの作成に必要なデータを全てプロパティとして持つオブジェクトを作成する(
formDataMockとする)。具体的にはformSchema、formLayoutなど。実際には他にも、カテゴリーフィールドやルックアップフィールドを表示するためのデータ、ユーザー選択フィールドを表示するためのユーザーの配列なども含む - 各フィールドを追加するための関数を
formDataMockに対して実行することで、そのフィールドを表示できるようなデータを各プロパティに追加する - 最後に、作成した
formDataMockを用いて、vi.spyOnで各データをモックするような関数を実行する
コードにするとこんな感じです。
// 1. セットアップ const formDataMock = initFormDataMock(); // 2-1. グループフィールドを追加 const { groupId, groupCode } = appendGroup(formDataMock, { properties: { open: "false", }, }); // 2-2. グループフィールドに文字列1行フィールドを追加する appendSingleLineTextToGroup(formDataMock, groupId, groupCode, { label: "グループフィールド内文字列1行フィールド", var: "グループフィールド内文字列1行フィールド", }); // 3. 実際のモック処理 setupFormDataSpy(formDataMock);
こうすることで、1つのフィールドを追加する処理を、例えば文字列(1行)フィールドを追加する関数であればappendSingleLineTextFieldのような関数に閉じ込めます。その中でformSchemaへのフィールド情報の追加とformLayoutへのフィールド情報の追加を一緒にすることで、先ほどのidの整合性問題を解決でき、コード行数の大幅な削減もできます。
ババロアチームではアーキテクチャに関する重要な決定をするときに、ADR (Architecture Decision Record)を書き、チーム内でレビューをもらうようにしています。これにより、チーム内で合意を取った上で実装を進められる他、後になぜこのような意思決定が行われたのかを参照できるようになります。
今回は上記のような使い方の流れを説明した上で、考えうる他のI/F案との比較、特殊フィールドの対応方針などを記載しました。
最初は一番基本的な文字列(1行)フィールドだけで実装したPRをマージしました。そうすると、後は他のフィールドについても同じように書けばいいだけなので、処理の共通化などを行ってからAIを駆使して残りのフィールドにも対応しました。
また、ババロアチームでは人間及びAIの可読性のために、積極的にJSDocを書くようにしています。今回も各フィールドを追加する関数に渡す引数が明確になるように、JSDocを書きました。
/** * SINGLE_LINE_TEXTフィールドをformDataMockに追加する * @param formDataMock - FormDataMockオブジェクト * @param newField - 追加するフィールドの定義。省略したフィールドにはデフォルト値が入る * @param fieldAccessibility - フィールドのアクセス権限 * @returns 追加したフィールドのID */ export const appendSingleLineText = (...) => { ... }
またモックヘルパーのディレクトリに、使い方の紹介やADRへのリンクを記載したりREADMEを追加したり、1つ簡単なintegテストを書いて実装例を残しておいたりと、他のメンバー(AI含む)が後から見たときに使いやすいような工夫をしました。
結果
アプリの設定としてフィールドを1つ追加するのに、改善前には以下のようなコードが必要でした。
// getFormSchemaのモック内で '2000': { id: '2000', label: '文字列(1行)', var: '文字列__1行_', type: 'SINGLE_LINE_TEXT', properties: { noLabel: 'false', required: 'false', defaultValue: '', expression: '', hideExpression: 'false', max: null, min: null, unique: 'false' } } // getFormLayoutのモック内で { type: 'SINGLE_LINE_TEXT', label: '文字列(1行)', var: '文字列__1行_', styleMap: { width: 193 } }
しかし、改善後だとデフォルトの設定値で良ければ、最も短くて以下の1行で済みます。
appendSingleLineText(formDataMock);
これにより、707行のintegテストは216行になり、他のintegテストでも同様の行数削減が見込めます。上述のようにidの整合性を取る処理も関数内で行っているので、開発体験が向上しました。 ヘルパー関数の準備には多少時間がかかりましたが、そのコストに見合う成果が得られたと思います。
また、最近ババロアチームではAI活用が進んでいます。AIに読んでもらうドキュメントを充実させていて、その1つとしてintegテストの書き方のガイドも含んでいます。そこに今回のモックヘルパー関数の使い方も追記することで、AIにintegテストを書いてもらうときにもモックヘルパー関数を用いて簡単に実装してもらえるようになりました。
今後の展望・まとめ
長期間苦しみながら書いていたintegテストを改善できてよかったです。
フロントエンド刷新プロジェクトにはスピードが求められているので、今後も開発を加速させるために改善できそうなところがあれば改善をしていきたいです。