こんにちは。 Necoチームの梅澤です。
従前、Neco ではクラスタのモニタリングに Prometheus を利用していましたが、最近これを VictoriaMetrics + VictoriaMetrics operator に変更しました。 本記事では、Prometheus で感じていた問題点と、それをどのように解決したかを紹介します。
感じていた問題点
我々が(オペレーターを利用しない) Prometheus で問題を感じていたのは以下の点になります。
- メトリクスの長期保存
- Neco では元々14日間ぶんを保存していました。しかし、過去のメトリクスは障害の継続的な調査にも有用であり、14日間では物足りなく感じていました。一方、 Prometheus はストレージの構造として長期保存をあまり想定していません。 https://prometheus.io/docs/prometheus/latest/storage/#operational-aspects
- HA 構成
- 以前の記事 にあるとおり、Neco では比較的頻繁に全体再起動を行っているのですが、その間にモニタリングが止まってしまうのは避けなければなりません。 Prometheus を単に複数並べた冗長化は可能ですが、その場合ストレージはそれぞれが別個に持つことになります。自インスタンスのデータが欠けても他インスタンスのデータは参照できないので、これでは具合が悪いです。
- マルチテナンシー
- Neco 環境では Kubernetes 環境を開発/運用しているチーム(Neco チーム)と、その上で動くアプリケーションを開発/運用しているチーム(テナント。複数ある)は別であり、それぞれがそれぞれのコンポーネントをモニタリングしています。モニタリングの系はそれぞれで立てる必要がありますが、できれば省力化したいところです。
代替案
メトリクスの長期保存について考えてみると、 VictoriaMetrics の他に Thanos, Cortex, M3DB といった選択肢が挙げられます。 VictoriaMetrics は以下のような特徴があります。
- 構成がシンプル
- タイムシリーズストレージとして効率的(圧縮比など)
- 機能ごとにうまく分割されており、 Prometheus から段階的に移行することも可能
- drop-in replacement を称しており、仮に全体を置き換えても、使用感が変わらない
VictoriaMetrics は元々 Prometheus 向けのリモートストレージとして開発されましたが、その後 Prometheus と互換性のあるスクレイピングやアラート判定のためのコンポーネントが追加され、Prometheus の drop-in replacement として十分な機能があります*1。 また、最近はオペレーター実装も開発が進んでいます。そのため、オペレーターを使ってモニタリングを全体的に VictoriaMetrics に移行することとしました。
VictoriaMetrics にするとどうなるか
メトリクスの長期保存
VictoriaMetrics は長期保存を想定して実装されています。 Neco 環境ではひとまず保存期間を1年強に設定して運用を開始しています。VictoriaMetrics は Prometheus と比較してデータの圧縮能力が高いため、長めの保存期間でもストレージの消費が少ないのがうれしいところです。
HA 構成
VictoriaMetrics には cluster version というものがあります。これは、データのレプリケーションと読み書きリクエストの分散によって、ストレージに関してスケールアウト可能なHA構成を実現するものです。また、スクレイピングやアラート判定についても単純に複数レプリカを立てることで HA 構成を取ることができます。
マルチテナンシー
オペレーターを導入したため、テナントはカスタムリソースをちょっと記述するだけでモニタリングクラスタを立てることができます。例えば、必要なコンポーネントは以下のカスタムリソースでデプロイできます。(Alertmanager 向けの設定を保存する Secret は省略)
apiVersion: operator.victoriametrics.com/v1beta1 kind: VMAgent metadata: name: vmagent namespace: tenant-ns spec: replicaCount: 3 remoteWrite: - url: "http://vminsert-vmcluster-largeset.monitoring.svc:8480/insert/0/prometheus/api/v1/write" --- apiVersion: operator.victoriametrics.com/v1beta1 kind: VMAlertmanager metadata: name: vmam namespace: tenant-ns spec: replicaCount: 3 configSecret: vmam-config --- apiVersion: operator.victoriametrics.com/v1beta1 kind: VMAlert metadata: name: vmalert namespace: tenant-ns spec: replicaCount: 3 datasource: url: "http://vmselect-vmcluster-largeset.monitoring.svc:8481/select/0/prometheus" notifiers: - url: "http://vmalertmanager-vmam-0.vmalertmanager-vmam.tenant-ns.svc:9093" - url: "http://vmalertmanager-vmam-1.vmalertmanager-vmam.tenant-ns.svc:9093" - url: "http://vmalertmanager-vmam-2.vmalertmanager-vmam.tenant-ns.svc:9093"
cluster version のストレージにはマルチテナンシー機能があって、テナントごとに自テナントだけが読み書きできるストレージのように振舞うことができます。しかし、Neco ではこの機能を使わずに、1つのストレージとして使うことにしました。この場合、テナントは自分でスクレイプしたメトリクスとNeco チーム側でスクレイプした cAdvisor や kube-state-metrics のメトリクスを組み合わせて独自のアラートルールを記述することができます。
さらなる可用性
実際にデータが保存されるストレージは Ceph RBD を使うことにしました。これにより、ストレージデバイスの故障に対しても耐性を持たせています。一方、そうすると今度は Ceph の障害が発生するとモニタリングが巻き込まれて一緒に止まってしまう懸念があります。これではいけません。
そこで、Ceph と本来のモニタリングクラスタをモニタリングするための最小限のモニタリングクラスタを、Ceph を使わずに用意することにしました。Neco では、この最小限のクラスタを smallset 、全体を監視する方のクラスタを largeset と呼んでいます。 smallset はあくまでも補助として使うもので、ストレージに TopoLVM を使い、保存期間も短めです。2つのクラスタを含むモニタリングの構成図を以下に示します。
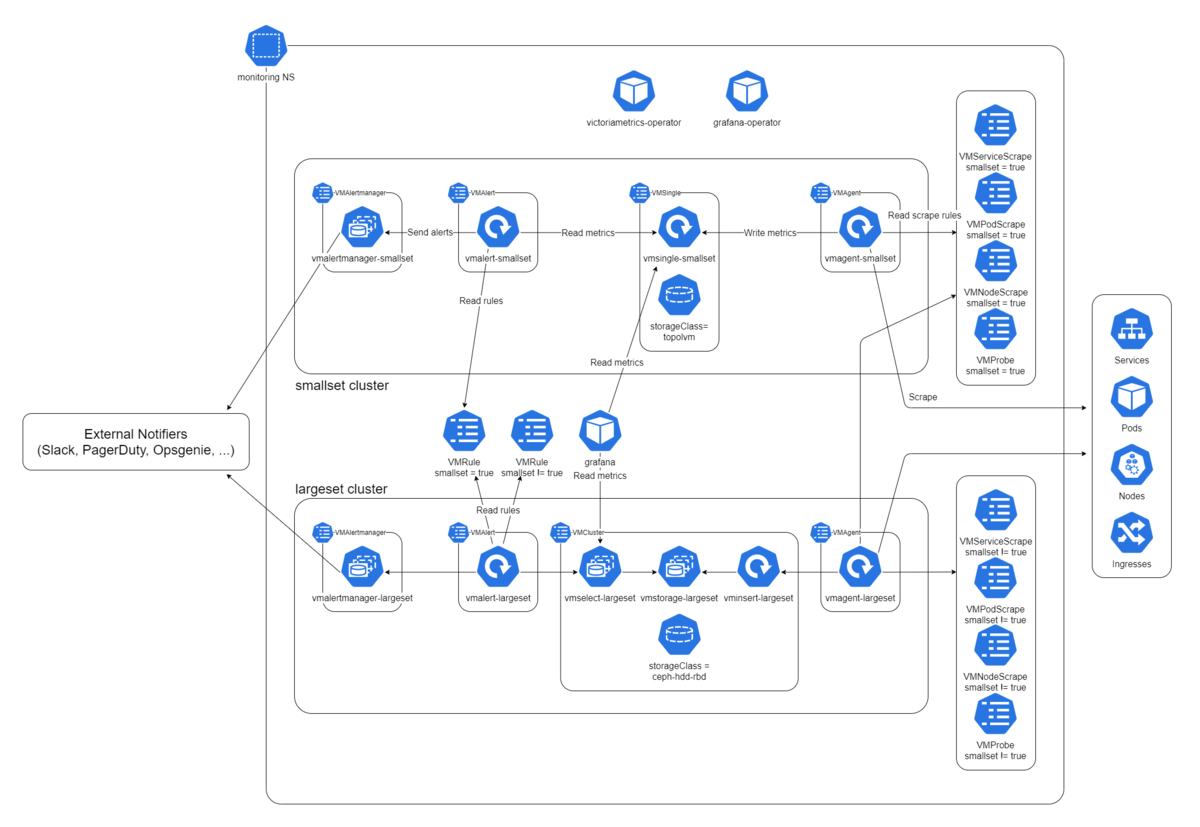
オリジナルサイズはこちら
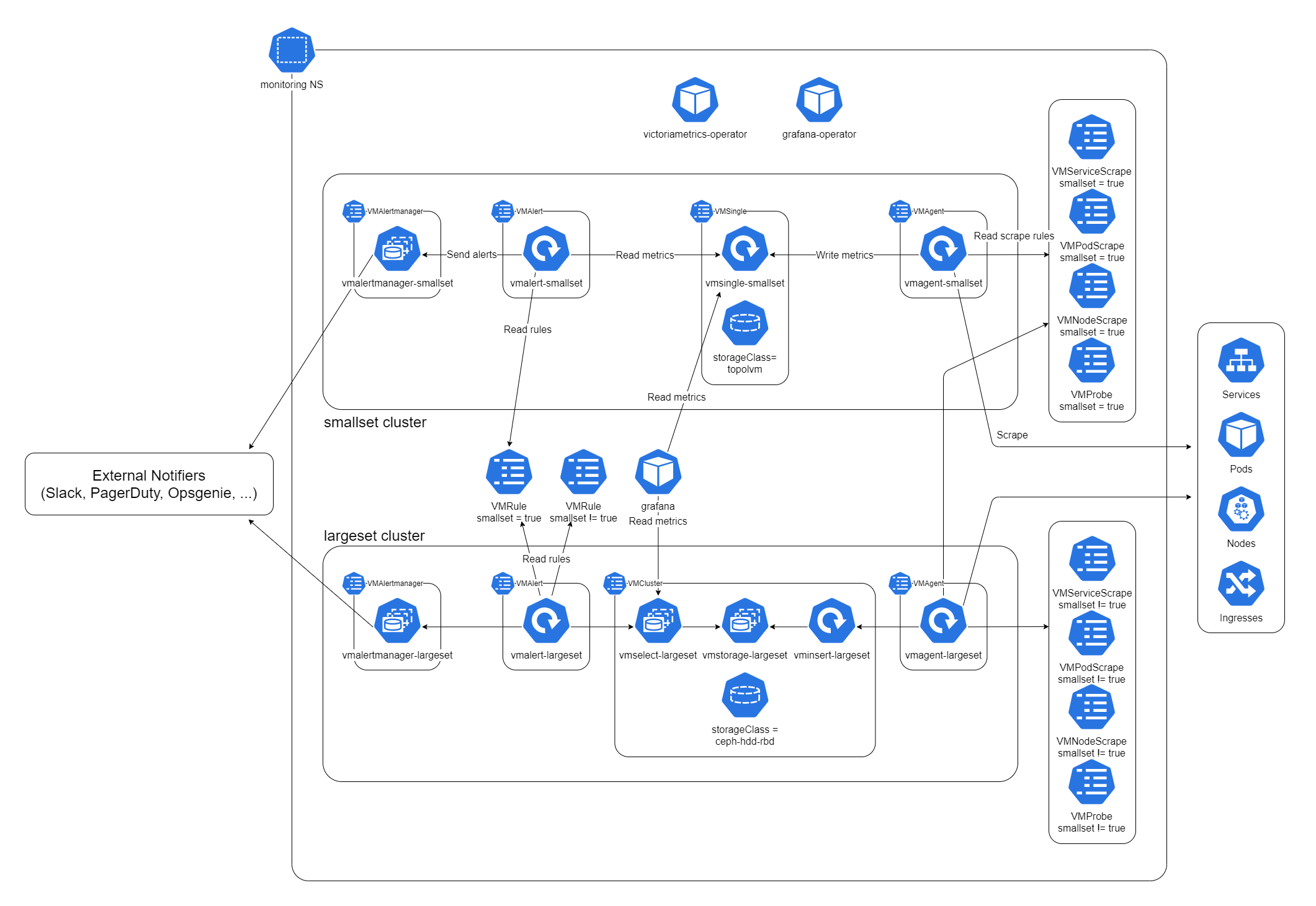{kind=link}
Grafana
メトリクスの可視化には Grafana を使うのが一般的です。VictoriaMetrics は上記のようにマルチテナンシーを実現しましたが、Grafana も同様にマルチテナンシーを実現する必要があります。 Neco では以前から grafana-operator を使用しており、ダッシュボード定義をカスタムリソースとして記述すると、Neco 環境内で稼働している Grafana にダッシュボードを追加できるようにしてあります。これにより、テナント側でダッシュボードを自由に追加することができます。
コントリビューション
VictoriaMetrics operator は開発が始まったばかりであり、いざ使ってみようとすると、やはりいろいろと問題や機能不足が見つかるものです。Neco チームでは継続的に upstream にコントリビューションをしています。現在、 feature request を投げると結構早く実装してもらえるのもうれしいところです。
最後に
本記事では VictoriaMetrics + operator を使用したモニタリングの構成例を紹介しました。高可用化を実現できたことで、ラック丸ごと障害の訓練時でも元気にアラートを発出できています。皆さんのより良いモニタリングライフの参考になれば幸いです。
*1:Alertmanager に相当するものは VictoriaMetrics の方には実装がないので、Prometheus の実装をそのまま使います。