こんにちは、Neco チームの 阪上 です。皆さんは Kubernetes クラスタのマシン全台の再起動オペレーションに丸一日かかったことはありますか? 手順を確認して雑談するだけで時間が過ぎて行く…穏やかですが、物足りなさも感じます。
そこで今回は、Kubernetes クラスタのサーバー全台を自動で宣言的に再起動する仕組みについて解説したいと思います。
背景
サイボウズでは自社データセンターでアプリケーションを運用するために Neco というインフラ基盤を開発しています。 ベアメタルで k8s クラスタを運用していると、ファームウェアの更新やセキュリティ対応のため、クラスタの全てのマシンを再起動したいことがあります。 しかしサイボウズのクラウド基盤 cybozu.com はメンテナンスを除いて 24 時間 365 日無停止での稼働が前提のため、再起動のためにサービスを停止することはできません。
これまではマシンを複数のグループに分割して手作業で少しずつ再起動していたのですが、社内で Neco の活用が広がるにつれて色々なサービスが動作するようになり、手動での再起動オペレーションが難しくなってきました。そこで我々は Neco の k8s 管理ツール CKE にマシン全台の再起動機能を実装することにしました。
Neco はなるべく人手を介さない自動運用を目標としているため、宣言的な設計になっていることが重要です。このことから、仕様は以下のように決めました。
- クラスタの管理者は全台再起動を一言宣言するだけ。全ては自動的に実行される。
- クラスタ上のサービスに影響が出ないようにする。
- 管理者は再起動の進捗を監視しない。トラブル発生時はアラートの形で自動的に通知される。
- 多少のサーバーが再起動に失敗しても処理を進める。故障などの理由で起動に失敗したサーバーがある場合は管理者にアラートで通知し、都度対応してもらう。
実装
処理の大枠の流れは次の通りです。
- 管理者が
neco reboot-workerと入力する。 neco reboot-workerコマンドが CKE の再起動キューにサーバーを二台ずつ登録する。- CKE が再起動キューを定期的に確認し、再起動待ちのサーバーがあれば順番に再起動する。
Neco の k8s クラスタは用途の異なる二種類のサーバー (compute, storage) で構成されています。 これらは再起動時に相互に干渉しないので、各一台ずつを同時に再起動します。
重要なのは 3 番目のステップで、サーバーを再起動する前にサーバー上の Pod を全て止めてもサービスに影響しないか確認する必要があります。 Kubernetes にはノードをメンテナンスするための標準機能があるので、CKE ではこれを使って全台再起動を実装しました。
Kubernetes のノードメンテナンスの仕組み
Kubernetes には、ノードを再起動するなどのシナリオでノード上の Pod を安全に削除するための標準機能があります。 ここではその使い方を解説します。
PodDisruptionBudget
k8s クラスタに参加しているノードを再起動するには、ノード上のアプリケーションを全て止める必要があります。 そのためアプリケーション開発者に Pod を冗長化してもらい、メンテナンスのために削除してもよい Pod の数を宣言してもらいます。 この宣言は PodDisruptionBudget (PDB) というリソースで管理します。
たとえば Service のバックエンドとして 3 個の Pod を作成し、1 つをクラスタ管理者が削除しても良いことにすると、メンテナンス中でも 2 個の Pod が動作することになります。メンテナンス中の耐障害性を確保したい場合は、その分の余裕も考える必要があります。
Pod の Delete と Evict
Pod の削除には Delete と Evict という二つの操作が用意されています。Delete (kubectl delete <pod>) は単に Pod を削除しますが、Evict を使うと削除後に PDB を満たせる場合のみ Pod を削除します。
Eviction は通常ノードのメンテナンスのために使われるので、ノード上の Pod を全て Evict する kubectl drain <node> というコマンドが用意されています。
削除した Pod が同じノードに再スケジュールされるのを防ぐため、kubectl drain を使うとノードには Unschedulable フラグがセットされます。
ノードのメンテナンスが終わったら、kubectl uncordon コマンドを使ってフラグを外します。

上の図では、クラスタの管理者が Node 1 の Pod を削除しています。Pod を 1 つだけ消してもよい設定の場合、このサービスの Pod はこれ以上削除できません。 したがって Node 2 の Pod も削除したい場合は Node 1 か Node 4 で Pod を起動する必要があります。 PDB の計算では Ready になっている Pod しかカウントされないため、Node 2 の Pod を Eviction で削除するには新しい Pod の起動完了を待つ必要があります。

PDB の書きかた
PDB の適切な設定はアプリケーションごとに異なるので、リソースとして宣言します。
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: sample-pdb spec: maxUnavailable: 1 selector: matchLabels: app: sample-app
停止してもよい Pod の数は色々な形で宣言できます。
maxUnavailable: 11 つだけ Pod を止めてもよいminAvailable: 44 個以上の Pod が Ready であればよいminAvailable: 80%Pod が全体の 80% 以上 Ready であればよい
PDB の対象となる Pod の数は Pod の ownerReferences に指定された Deployment や StatefulSet のレプリカ数で決まります1。
適切な PDB の内容は主にアプリケーションがステートフルかステートレスかによって異なります。
ステートフルアプリケーションの場合は通常 maxUnavailable を 1 にするか、minAvailable に分散合意に必要な quorum の数を指定します。
ステートレスアプリケーションの場合は負荷に応じて適切なパーセンテージを指定することができます。
PDB の設定の詳細は Kubernetes の公式資料 に書かれていますのでご参照ください。
Eviction API
ノードからの Pod の退避は kubectl drain で実行できますが、より fine-grained な操作が必要な場合は Eviction API を使うことができます。
Eviction API では、Pod 名を指定して個別に Evict することができます。
{ "apiVersion": "policy/v1beta1", "kind": "Eviction", "metadata": { "name": "sample-pod", "namespace": "sample-ns" } }
CKE では、開発環境のアプリケーション Pod を強制的に削除するために Eviction API を活用して Delete と Evict を使い分けています。 Go からは Evict 関数として呼び出せます。
import ( policyv1beta1 "k8s.io/api/policy/v1beta1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) clientset.CoreV1().Pods(namespace).Evict(context, &policyv1beta1.Eviction{ ObjectMeta: metav1.ObjectMeta{Name: name, Namespace: namespace}, })
モニタリングとアラート
再起動の進捗を知るため、Prometheus のメトリクスとアラートを設定しました。
- 再起動キューのエントリ数をメトリクスにして Grafana で確認できるようにしました。
- キューのエントリ数が 1 時間以上減らない場合はアラートを上げるようにしました。 これは通常 PDB 違反を意味しています。たとえば、StatefulSet を構成する Pod が乗ったノードが故障してコンテナを再作成できなくなり、そのまま他の Pod が乗ったノードを再起動しようとしている場合などです。
- ノードが長時間 NotReady の場合はアラートを上げるようにしました。
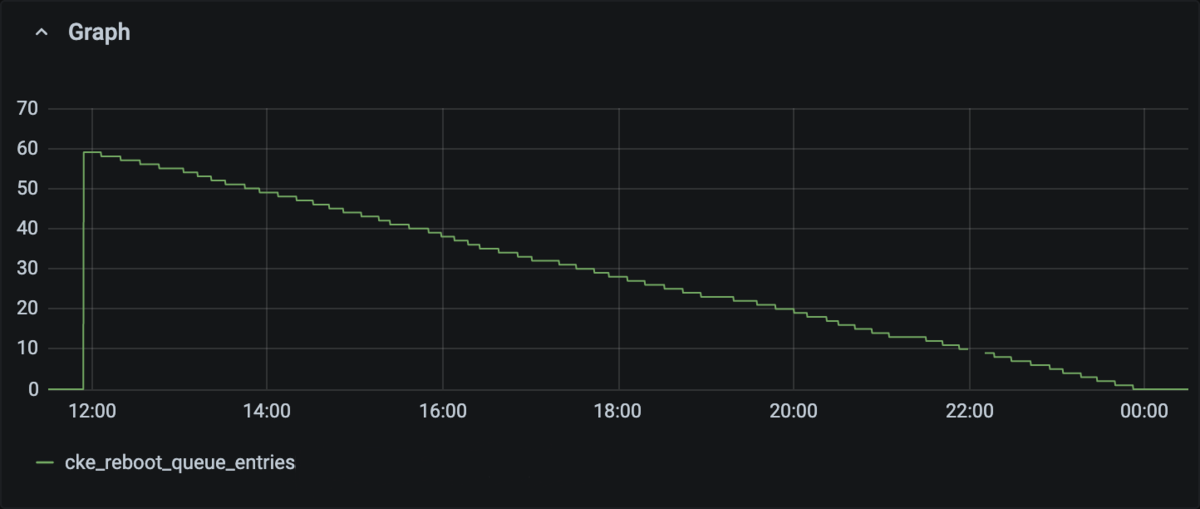
こちらが実際の再起動の様子です。順調に処理できているのが分かります。
便利な機能
全自動とはいえ、夜間にサーバーを順次再起動していくのは不安なこともあります。 またトラブルが発生した時には処理を中断したいこともあるかもしれません。 そのため、管理者がコマンドを入力するとキューの処理を一時停止することもできるようにしました。
結果
これまで丸一日かかっていた全台再起動の手順が neco reboot-worker と入力するだけ、5 秒で終わるようになりました。
進捗を監視する必要もなく、操作後は他のタスクに集中できるようになりました。
このシステムを使って何度か全台再起動を実施しましたが、特に問題なく無事に再起動できています。
今後、サーバー台数が増えてきたらラック単位での再起動を検討する予定です。