こんにちは。サイボウズ・ラボの西尾泰和です。 今回は「おすすめグラフ」の裏側について紹介したいと思います。
「おすすめグラフ」って何?
「おすすめグラフ」は弊社のデータベースアプリ「kintone」に3月から搭載される新機能です。 データ一覧の画面から ワンクリック するだけで、コンピュータがそのデータを解析し、よさそうなグラフをおすすめしてくれる機能です。

おすすめグラフ
今回は、この機能が、何を解決するために、どうやって実現されているのか、を簡単にご紹介します。
モチベーション
kintoneは自由度が高く、いろいろなことができるアプリです。グラフ一つとっても、色々な集計の仕方ができます。 しかし自由度が高いアプリは設定できることも多くなります。そのため、ユーザは「何をどう設定したら自分のほしいものが得られるのだろう?」と悩んでしまいがちです。
そこで「おすすめグラフ」です!ユーザに0から設定させるのではなく、おすすめの中から自分のほしいものを選べるようにしました。 もちろん、もし必要であればそこからさらに設定を調整することもできます。あらかじめ設定済みの候補を提案することで、最初の一歩を楽にするわけです。

おすすめグラフ Before / After
よいグラフを上に!
とはいえ、この「おすすめ」が100件も200件もあったのでは「たくさんありすぎて選ぶのが苦痛…」となってしまいます。「よいグラフ」がなるべく上位に来るしくみが必要です。それにはどうすればよいでしょうか?
それには、グラフの「よさ」を判定する評価関数を使います。
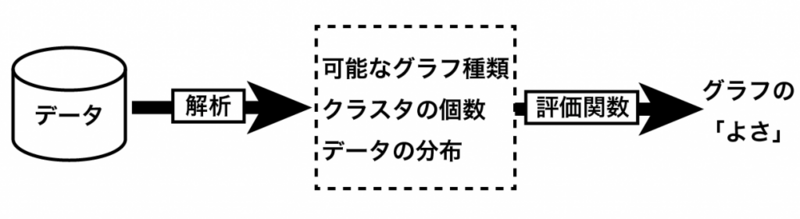
グラフの「よさ」を決める仕組み
「おすすめグラフ」のシステムは、まずデータを解析し、どんな種類のグラフが可能か、クラスタの個数はいくつか、データはどんな分布になっているか、などの特徴量を抽出します。そして、その特徴量を評価関数を使って「グラフのよさ」を表す実数値に写像します。
たとえば、データのある軸が「人」でもう一つの軸が「数値」だとしましょう。これを折れ線グラフで描くのは変です。つまり棒グラフか円グラフで描いたほうが「よいグラフ」ということです。
棒グラフと円グラフではどちらが「よいグラフ」でしょうか。それには例えばクラスタの個数が影響します。クラスタが多い場合、円グラフで書くと細かいパイがたくさんできて見づらいグラフになります。つまりクラスタの数が増えるほど「棒グラフの好ましさ」が「円グラフの好ましさ」に比べて大きくなるわけです。
また、クラスタの個数が同じ円グラフが複数あったとしましょう。データの分布によってはグラフの好ましさが異なります。どれくらい「意味のありそうなグラフか」を分布のエントロピーを元に計算し、評価に使っています。
このようないろいろな要素を勘案して、評価関数が最終的な「グラフのよさ」を決定します。後はこの「よさ」が大きいものからおすすめしていけばよいわけです。
ユーザを待たせない
ところで、この処理にはユーザの入れたデータによってかかる時間が変わります。全部の解析が終わるまでユーザを待たせると、データによってはユーザがイライラしてしまいます。どうすればよいでしょうか?
「おすすめグラフ」のシステムでは、上記の解析処理が非同期に実行されます。解析処理を行うスレッドは候補をどんどんと優先度つきキューに追加して行きます。そしてユーザにおすすめグラフを出す際には、その優先度付きキューの先頭から取り出して「現時点で一番よいグラフ」を提示します。これによってユーザを待たせる時間を削減しつつ、なるべくよいグラフが出るようにしているわけです。
実際にはもっとユーザのためを思って工夫した結果、優先度付きキューが二段構えになっていますが、煩雑な話になるので割愛します。
まとめ
簡単にですが新機能「おすすめグラフ」の裏側について紹介させて頂きました。楽しんで頂けたでしょうか?