はじめに
こんにちは、Necoプロジェクトのsatです。Necoプロジェクトではサイボウズのクラウド基盤であるcybozu.comのストレージに関する様々な要件を満たすために分散ストレージソフトウェアCephを導入する予定です。本記事ではCephとは何者かについて紹介いたします。Cephが持っている機能は膨大な数にのぼるため、ここでは一部の機能に絞って紹介したいと思います。
概要
Cephはオープンソースの分散ストレージソフトウェアです。2004年以前からカリフォルニア大学で開発され、2006年にオープンソース化されました。現在ではRed Hat社をはじめとするさまざまな企業、あるいは個人によって活発に開発されています。Cephは例えばOpenStack のストレージ機能(Cinder, Swift, やGlanceなど)の選択肢の1つとして使われています。
Cephは複数台のマシン上のストレージデバイスを束ねて一つのストレージプールを作り、そこからPOSIX-like*1なブロックデバイス(RBD)、S3やSwift互換インターフェースを持つオブジェクトストレージ(RADOSGW)、ファイルシステム(CephFS)を切り出してユーザに提供します。

ここで用語をいくつか定義しておくと、CephにおいてはCephクラスタを構成する個々のマシンをノード、その中の個々のストレージデバイス(ないしパーティション)をObject Storage Device(OSD)と呼びます。上図においては円筒型の図形がそれに対応します。
なおNecoではCephFSは使わずにRBDとRADOSGWだけを使う予定なので、これ以降ファイルシステムについては述べません。
データの冗長化(RADOS)
Cephはストレージプール上にReliable Autonomic Distributed Object Store Object(RADOS)というオブジェクトストレージシステム*2を持っており、RBDやRADOSGWなどはRADOSオブジェクトと呼ばれるRADOS上の個々のオブジェクトの塊として提供されます。個々のRADOSオブジェクトは通常複数のレプリカが作成され、それぞれ別のOSDに保存することによってデータの冗長化を実現しています。以下レプリカ数3のRBDを示した図です。
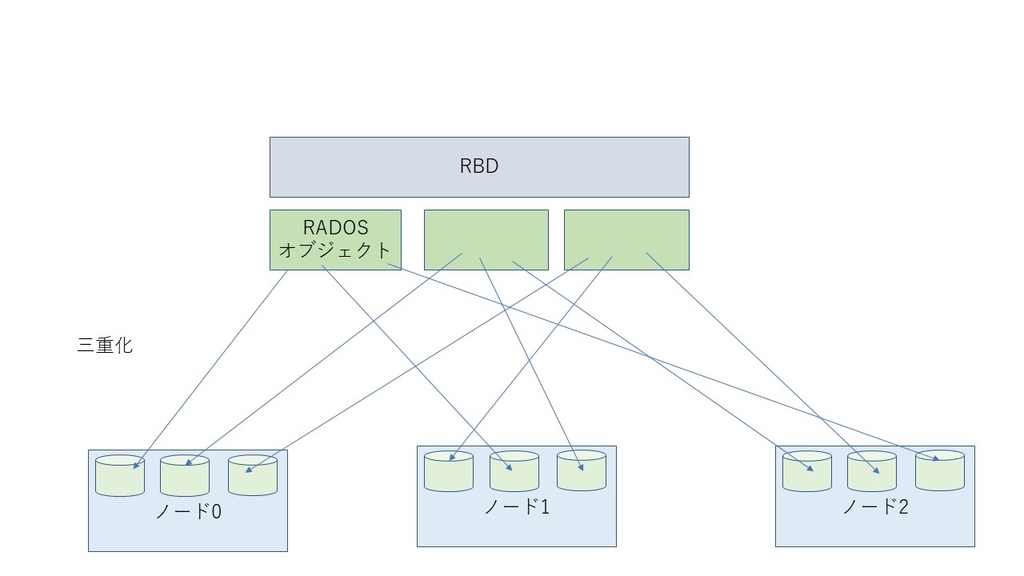
データのレプリカを持つことによって個々のOSDに問題が発生したときもデータは失われず、運用が継続できます。それだけではなく、レプリカ数が2なら運用を継続するものの、1になったらそのオブジェクトには冗長度が2以上に回復(冗長度を回復させるリバランス処理については後述)するまでアクセスを失敗させることもできます。
データ配置位置の決定方法(CRUSH)
個々のRADOSオブジェクトのレプリカをどのOSDに配置すべきかはどのようにして決定するのでしょうか。CephにおいてはControlled Replication Under Scalable Hashing(CRUSH)というアルゴリズムを用いて、RADOSオブジェクトの名前のハッシュ値、および現在生存しているOSDのリストをもとにRADOSオブジェクトの配置位置を計算によって求められます。これによってHadoopのNameNodeのような「どのデータをどこに保存すべきか」ということを保存した巨大な管理データを持つ必要がありません。それに加えてI/Oが発生するごとにそのようなデータにアクセスする必要がないので、高速なI/Oが期待できます。
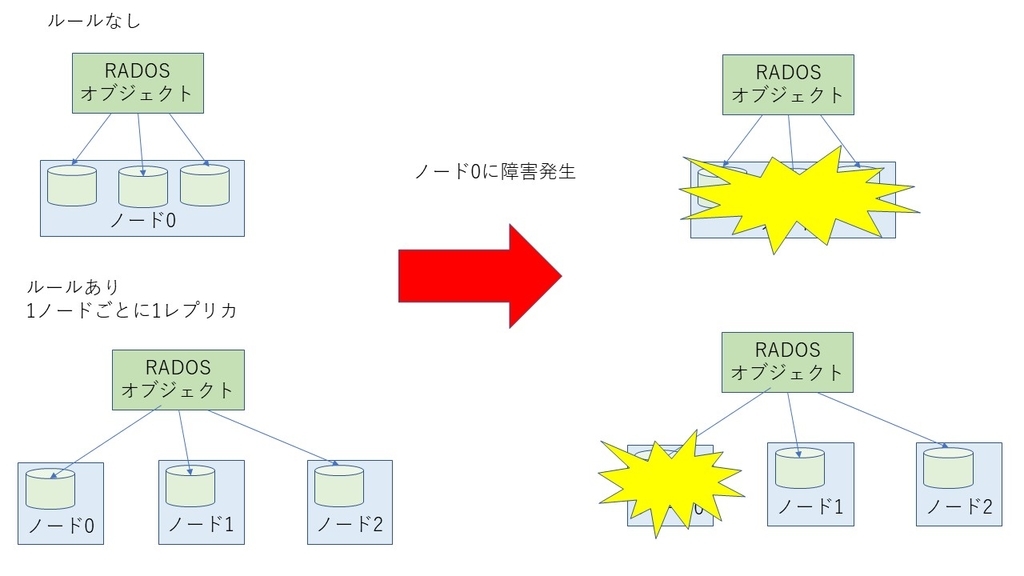
CRUSHはOSDの物理的な位置を考慮してデータを配置するルールを設定できます。具体的には、あるRADOSオブジェクトをすべてのOSDの間でランダムに配置する場合を考えると、すべてのレプリカが同じノード内のOSDに配置されてしまって、1つのノードに問題が発生しただけで当該データにアクセスできなくなるということが考えられます。このような状況を避けるために、Cephでは「オブジェクトは同じノードには1レプリカしか持てない」というルールが決められます。
クラスタの管理方法(モニタ)
クラスタの状態は1つないし複数の奇数個のノード上に分散配置されたモニタという機能によって管理します。モニタが複数個存在することによって、たとえば1つのモニタが応答しなくなっただけでクラスタ全体が機能しなくなるというような状況が避けられます。
モニタは「クラスタ内にどのようなOSDがあって、どのOSDにはアクセス可能か」といった情報をまとめたCRUSH mapという(上記NameNodeなどに比べると)小さなデータを持っています。モニタおよびOSDの間では定期的に死活監視処理が動作しており、状況が変わるたびにCRUSH mapは更新されます。モニタ同士はPaxosという合意形成プロトコルを用いて通信し合うことによって、クライアントないしOSDと通信する際には常に最新のCRUSH mapを元に判断ができるようになっています。
クライアントがデータの書き込み要求を出すときは下図のような流れで実際のI/Oが動作します。

クラスタの拡大
Cephは運用を止めることなく、いつでも新しいOSDをクラスタに登録することによって容量を拡大できます(縮小もできます)。OSDを足した場合にはCRUSH mapが更新され、リバランスと呼ばれるデータの移動が発生することによって、クラスタ内のデータの偏りを防ぎます。
セルフヒーリング
クラスタ内のノードがダウンするなどの理由によってOSDがクラスタから見えないという状態が長時間続くと、Cephは当該OSDはダウンしたものとみなしてCRUSH mapを更新します。ここでリバランス処理が動作して、ダウンしたOSDのデータは他のレプリカのデータをもとに別のOSDに移動することによってオペレータの介在なしに冗長度が自動回復します。ダウンしたノードが再びクラスタが認識すると、データは再びもとのOSDに戻ります
bit-rot耐性
bit-rotという言葉をご存じでしょうか。ストレージデバイス上のデータは、ソフトウェアにバグが無い場合にもデバイスの物理的な問題によってビットが反転してしまうなどの理由によって壊れてしまうことが稀にあります。これがbit-rotです。この問題の恐ろしいところは、何も対策をしていなければデータが破壊したことにユーザは気づかないということです。
Cephに数年前導入されたBlueStoreというストレージバックエンド*3を用いればこの問題を解決できます。BlueStoreにおいてはデータをOSDに保存する際に、データのチェックサムも同時に保存します。OSDからデータを読み出す際に読みだしたデータのチェックサムと保存しておいたチェックサムが一致しない場合はそのデータは壊れているものとみなします。このときレプリカが存在すれば自動的にレプリカから正しいデータを復元させられます。
おわりに
本記事はCephの概要について述べました。今後も本記事では書ききれなかった機能の紹介などについての記事を書く予定です。また、ここではCephの良い面だけ紹介しましたが、世の中に完全なソフトウェアはなく、Cephもまたその例外ではありません。今後Cephを使うにあたって克服しなければいけない課題(たとえば大量のリバランス処理によるネットワークの飽和)、およびNecoチームではそれをどのように解決するかについて紹介する記事を書く予定です。
最後になりますがNecoチームではCephおよび分散ストレージシステムを自動的に構築・管理するシステムの開発者を募集中です。ふるってご応募ください!