こんにちはサイボウズ・ラボの光成です。
先日社内でハッカソンというイベントがありました(Cybozu Hackathon開催)。私はMicrosoft Office 2007ファイルに対するパスワード攻撃の実装実験を行ってみたのでその報告をします。
パスワード攻撃とは、暗号化されたOfficeのファイルに対して総当たり、あるいは英単語辞書、よく使われているパスワード一覧などにあるパスワードを一つずつ試して正しいパスワードを見つけることです。
そのような機能を持つツールは既にいくつもありますが, 自社で保持しているといろいろなサービスに組み込みやすいかなと思って作ってみました。
暗号化フォーマットの仕様
Office 2007以降で使われるファイルの暗号化フォーマットの仕様は[MS-OFFCRYPTO]: Office Document Cryptography Structure Specificationで公開されています。 この仕様書は100ページ以上もあり、なかなか複雑なのですが、パスワードとsalt(ランダムな数)から秘密情報を取得する部分のコードは次のようになります。
std::string hashPassword(cybozu::crypto::Hash::Name name, const std::string& salt, const std::string& pass, int spinCount)
{
cybozu::crypto::Hash s(name);
std::string h = s.digest(salt + pass);
for (int i = 0; i < spinCount; i++) {
char iter[4];
cybozu::Set32bitAsLE(iter, i); // iをlittle endianとしてメモリに書く
s.update(iter, sizeof(iter));
s.digest(&h[0], &h[0], h.size());
}
return h;
}
saltとpassを連結してハッシュ(大抵SHA-1)をとり、そのハッシュ値に現在のループ番号を連結させて再度ハッシュをとる操作をspinCount回行います。spinCountの値は通常1万から10万です。
spinCountを回す操作はストレッチングと呼ばれます。 万一、ファイルが漏洩したときにパスワードの総当たり攻撃をさせにくくするためのものです。たとえば10万回ループさせれば攻撃能力を10万分の1にできます。
さて、Xeon X5650 2.6GHzのマシンでHash関数としてOpenSSLのSHA-1を呼び出してテストするとSHA-1の処理速度は4.4M回/秒となりました。これは初期化や値の設定の部分も含んだ数値です。
つまりストレッチングされていないとパスワードチェックを1秒あたり440万回できるのですが、10万回のストレッチングをしていると44回しかできないということです。ストレッチングの効果がよくわかります。
なお、ストレッチングはパスワードの総当たりをしにくくするためのものですが、それでも安易なパスワードを使っていると辞書攻撃で破られてしまいます。正しく複雑なパスワードをつけるようにしましょう。
コードの高速化と整理
それはさておき、このストレッチングの処理がいかに重たいかがわかります。そこで以降では、このループ処理を高速化してみることにしました。
SHA-1では入力値をbig endianとして扱い、計算し終わった後の値をbig endianとして出力する仕様となっています。
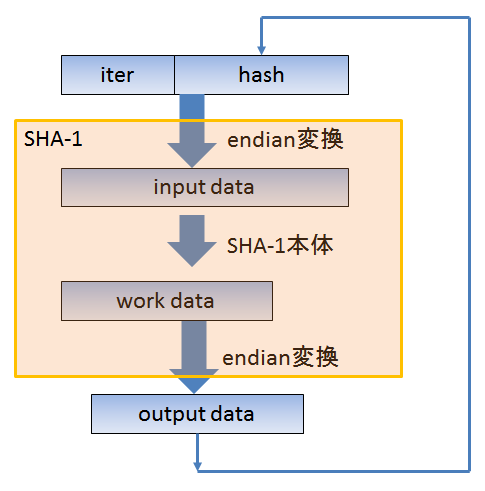
SHA-1のストレッチングの構造
すると上記のようにspinCount分だけ回す場合は入出力におけるbig endianに変換部分は相殺するため削除できます。また入力値が常に20byteになるためpaddingなどの処理も簡略化できます。
OpenSSLのSHA-1は極めて高速な関数ですが、アセンブラで書かれているためそのような変更をするのは困難です。そこでOpenSSLは使わず自前で書いた素直なC++のSHA-1を使ってストレッチング向けに処理を省いたコードを作ることにしました。
当然、最初はOpenSSLを呼び出した方が速かったです。しかし細かい最適化や処理のメモリ移動の簡略化を行うことでpureなC++のままでも5.3M回/秒となりOpenSSLを使ったものより速くなりました。
コードの並列化とSIMD化
コードの高速化と整理が一通り終わったので次は並列化を行います。パスワードをチェックする関数はデータの依存性が少ないため並列化は極めて容易です。
Xeon X5650は物理12コア、論理24コアのCPUです。スレッド数を1から24まで変化させてSHA-1の処理回数をプロットしました。
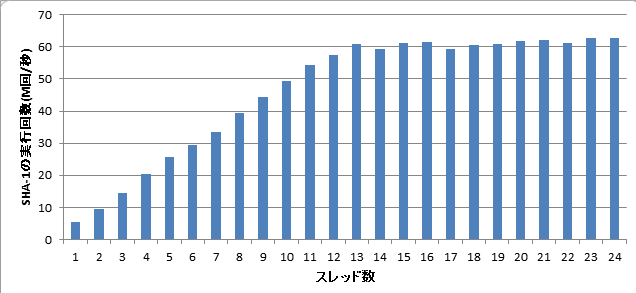
スレッド数に応じたSHA-1の処理数
だいたい12~13スレッドで頭打ちになっていることがわかります。今回のような同時に算術演算をフルに使う処理の場合、ハイパースレッディングによる効果は殆ど期待できません。物理コア数を超えて並列処理させても速くなるどころか、むしろ遅くなることもあります。
次にSIMD化を行いました。SHA-1は内部で80個の32bit整数を一時変数として持ち, それらに対してadd, xor, not, and, or, shiftなどの処理を行います。分岐や32bitを超えるデータの演算はないためSIMD化しやすいです。SSE2では32bit整数を4個並列に処理できます。よって一度に4個のパスワードを処理させるよう内部データを(4byte x 4) x 80の構造に変更します。
+, ^, &, |などを演算子オーバーライドし、処理単位をtemplateクラスパラメータとすることで、元のコードを比較的簡単にSIMD化できました。1コアあたりの性能は5.3M回/秒から15.3M回/秒と3倍近い性能となりました。12コアで走らせると155.7M回/秒となり最初から比べると35倍の高速化です。
最後にHaswell用最適化としてAVX2を利用しました。AVX2はHaswellから搭載された機能で32bit整数演算を8並列で行えます。入力データを(4byte x 8) x 80の構造に変更してAVX2対応させると52.6M回/秒となりました。SSE2の場合は26.3M回/秒でしたのでほぼ2倍です。ここまできれいにスケールする例は珍しいです。
更に4コアを使って4並列処理をさせると190M回/秒となり、12コアのXeonよりも速い値になりました。シングルコアでOpenSSLのSHA-1を呼び出した場合は8M回/秒ほどでしたのでHaswellの1コアでOpenSSLを使った場合と比べて24倍ほどの高速化ができました。
まとめ
最終的に20byteのSHA-1を秒間1~2億回計算できることがわかりました。GPU speed estimations for MD5/SHA1/Office 2007/WPA/WinZip/SL3によると、これは3~4年前のGPUの性能に近いようです。最近のGPUではその10倍ぐらいは出せるようです。次はGPUでどれぐらい速度がでるのか試してみようと思います。