こんにちは。Necoチームの池添です。 最近にわかにFlaky Test界隈が盛り上がりを見せているようです1,2,3。 この流れに乗じてNecoプロジェクトにおけるFlaky Testとの戦いについて紹介したいと思います。
Necoプロジェクトにおけるテスト
Necoプロジェクトでは、自社データセンター上のインフラ構築と運用を自動化する仕組みを開発しており、サーバのプロビジョニングから、Kubernetesクラスタの構築、Kubernetesクラスタ上で動くさまざまなアプリケーションのデプロイ、各種ソフトウェアやOSのアップグレードなどを自動化しています。
本プロジェクトでは「Test Everything」を設計原則のひとつとしており、VMを利用した仮想データセンターの仕組みを用いて、開発した自動化の仕組みを毎日テストしています。
詳しく知りたい方は下記の記事もご覧ください。
Flaky Testとは
Flaky Testとは、実行結果が不安定なテストのことです。 コードを変更していないにもかかわらず、実行するたびにテストが成功したり失敗したり結果が変化するため、原因が追及しにくく非常にやっかいな問題です。
Necoプロジェクトのテストでは10台以上のVMを利用しており、Kubernetesクラスタ上には数十のアプリケーションがデプロイされていて、サーバの再起動やアプリケーションのアップグレードを含む様々なテストを実施しています。 このようなテストでは、結果が不安定になってしまうことも想像に難くないでしょう。
Flaky Testがあると何が起こるのか
Flaky Testが常態化すると、テストが失敗したときに失敗原因を精査せず「また不安定系か。とりあえずRerunしよ。ポチッ」という対応になりがちです。
しかしこのような対応をしてしまうと、本来テストで発見すべき不具合を見逃すことにもつながります。
また、我々のプロジェクトでのテストは1回に1時間半程度要するため、再実行のための待ち時間が発生し、開発効率の低下につながります。
さらに、テストの実行にはクラウドのインスタンスを利用しているので、再実行のたびに費用がかかってしまいます。
Flaky Testを完全になくすことは難しいのですが、このような問題を回避するためにもFlaky Testを減らす努力を怠ってはなりません。
過去3ヶ月間の分析
それでは、我々のプロジェクトにおける、過去3ヶ月のmasterブランチでのテスト成功率を見てみましょう。
masterブランチでのテストは、いったんフィーチャーブランチでテストが通った後に実行されるものであるため、ここでの失敗はFlaky Testの可能性が高いと言えるでしょう。
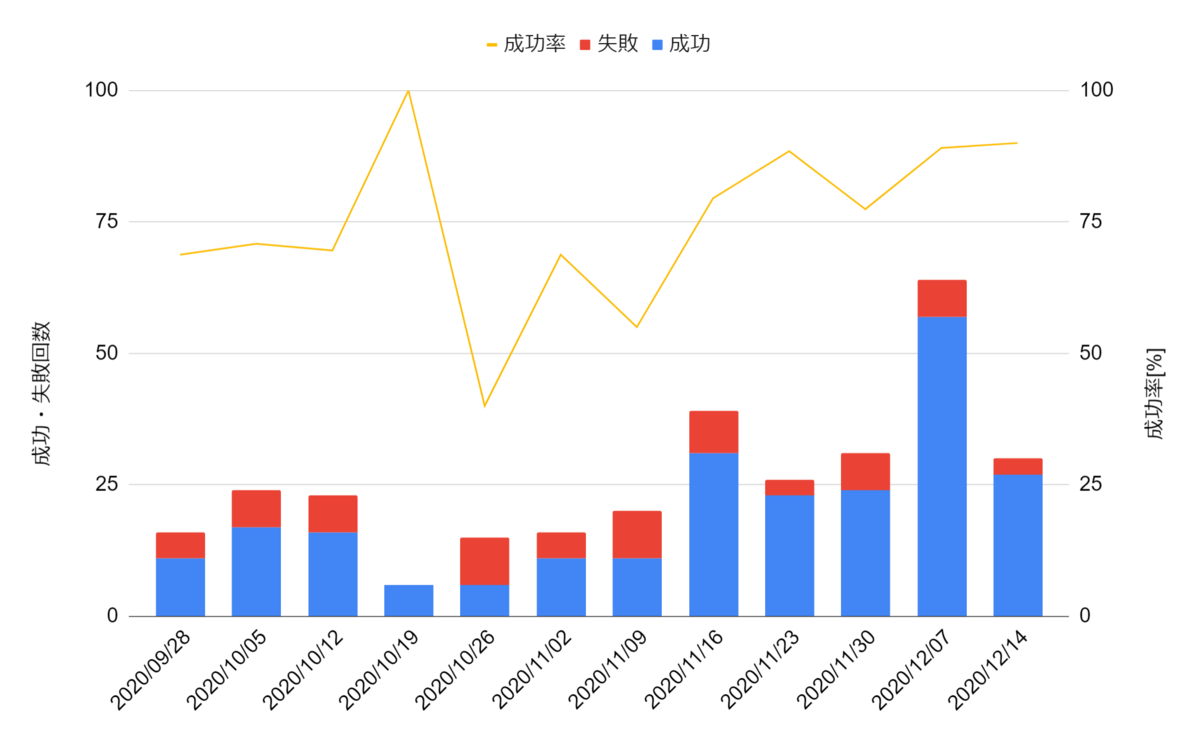
このグラフをみると、10月頃のテスト成功率が大きく下がっていることが分かると思います。 この頃我々は、テストの不安定さに非常に悩まされていました。
10/19週に関してはテスト成功率こそ100%ですが、試行回数そのものが非常に少なくなっています。 これは、テストが不安定なためmasterブランチにマージすることすら困難な状況になっていたからです。 テストが不安定になるとmasterへのマージ回数も減り、開発効率が低下してしまうことが窺えます。
そこで10月から11月にかけてFlaky Testの改善に力を入れました。 その結果、12月にはテスト成功率90%程度まで改善することができました。
分類
過去に我々が直面したFlaky Testの要因を分類して紹介したいと思います。
外部要因
まず1つめは外部要因によるものです。
我々のテストは、パブリッククラウドのインスタンスを利用して実行しています。 そのためたくさんのテストを同時に実行すると、インスタンスのクォータ制限に引っかかったり、利用しているリージョンでのインスタンス不足により、テストが実行できなくなるケースがあります。
また、我々が開発しているプラットフォームは日々成長しています。 デプロイするアプリケーションの追加に合わせて、インスタンスを増強してやらないとリソースが逼迫してテストが不安定になります。
さらに仮想データセンターを実現するために、1つのインスタンス上に複数のVMを立ち上げる方式(Nested VM)をとってます。 このNested VMにもテストを不安定にさせる問題があります。 この問題に関しては社内のLinuxカーネル有識者と協力して調査をおこなったのですが解決には至っていません。 今後はクラウド環境上でのNested VMを利用したテストを止め、自社データセンターのベアメタルマシン上でテストすることを計画しています。
我々のインフラはGitHubやコンテナレジストリ、パブリッククラウドのDNSサービスや、証明書発行サービスなどに強く依存しています。 これらのサービスに障害が発生した場合にも、我々のテストは失敗することになります。 複数のクラウドサービスを利用してフェイルオーバーすれば、障害に備えることもできますが、このあたりは必要とする可用性とコストの兼ね合いになってくるでしょう。
利用しているソフトウェアの不具合
我々のプラットフォームでは、Kubernetesをはじめ、Rook, ArgoCD, Contourなど、非常にたくさんのOSSを利用しています。 Flaky Testの要因として、これらのソフトウェアの不具合が見つかることも多々あります。
例えば、最近では下記のような問題が見つかりました。
- Kubernetesのクライアントにおいて、巨大なリソースを更新する際に必要以上に時間がかかってしまいタイムアウトする問題
- kube-proxyにおいて、IPVSモードでロードバランシングアルゴリズムにsource hashingを選択した際、古いIPVSの設定が残ってしまい、まれにルーティングに失敗する問題
- ArgoCDにおいてNetworkPolicyを適用する際に、ArgoCDの同期処理が停止してしまう問題
このような問題が見つかった場合は、ソフトウェアの提供元にIssueやPRを発行することになります。 PRが取り込まれるまでの間は、ワークアラウンドを見つけたり、パッチをあてビルドし直したソフトウェアを利用したりして、問題を回避します。
自分たちのアプリケーションの不具合
自分たちが開発しているアプリケーションの不具合ももちろん見つかります。 各ソフトウェアは、単独でのテストは実施していますが、仮想データセンター上にデプロイして他のソフトウェアと組み合わせることによって初めて発覚する不具合もあります。
最近では、下記のような問題が見つかりました。
- Kubernetesクラスタを管理するソフトウェア(CKE)のリーダーが切り替わった際に、CKEが管理するetcdの設定が変わってしまい、負荷状況によってetcdがタイムアウトしてしまう問題
- Kubernetes上のPodのlivenessProbeの設定がシビアすぎるために、負荷状況によってPodが起動する前にkillされてしまう問題
- ArgoCDによるアプリケーションのデプロイ時に、アプリケーション間の依存関係を考慮していなかったために、タイミングによってデプロイに失敗してしまう問題
仮想データセンター上で複雑な構成のテストを実施することで、アプリケーション単独のテストでは見つけられない不具合も発見できており、有意義なテストが実施できていると言えるでしょう。
Flaky Testとどう立ち向かうか
次に、我々がどのようにFlaky Testの対策をおこなっているのかをご紹介したいと思います。
Be Declarative
Necoプロジェクトにおけるもうひとつの重要な設計原則として「Be Declarative」があります。 これはKubernetesの特徴でもあり、あるべき理想の状態を宣言しておくと、その状態に収束するようにソフトウェアが自動的に調整するというアーキテクチャスタイルです。 Necoプロジェクトでは、サーバのプロビジョニング、Kubernetesクラスタの構築、サーバの再起動オペレーションなど、様々な運用をDeclarativeな仕組みで自動化しています。
Declarativeなアーキテクチャスタイルで実装されたシステムは、不安定な要素が含まれていたとしても自動的に復旧をおこないます。 テストで不安定な問題が見つかった場合は、Delcarativeな仕組みで解決ができないか考えてみるとよいでしょう。
ただし、最終的に理想の状態に収束したとしても、途中で重要な問題が発生している可能性もあります。 このような問題を見逃さないためにも、メトリクスの収集・分析・アラートは正しく設定しておく必要があります。
継続的な改善
Flaky Testは完全になくすことは難しいため、継続的な対応が必要となります。
Necoプロジェクトでは3人程度のチームが4つありメンバーをローテーションしているのですが、そのうちの1つのチームがFlaky Testの修正を担当するようにしています。 CIテストの失敗が発生するとSlackにアラートが飛んでくるので、テストを実行しているインスタンスに乗り込んで原因を調査するようにしています。 不具合はなかなか再現しなかったり、再現してもすぐに消えてしまったりするものもあるので、素早い対応が重要です。 オンコールの障害対応と似ていますね。
また原因の調査にはログが重要です。CIでは必要そうなログはとりあえず全部保存しておくのがよいでしょう。
お金で解決
仮想データセンターをテストするためには非常にたくさんのリソースを必要とします。 このリソースをケチるとテストが不安定になりがちです。
お金で解決できる問題であれば、お金を使うのがいいでしょう。
まとめ
本記事ではNecoプロジェクトにおけるFlaky Testとの戦いの記録を紹介しました。
我々は2年以上このFlaky Testと戦い続けてきましたが、銀の弾丸はなく、愚直に向き合うしかありません。
本記事で紹介した内容が、皆様のFlaky Testとの戦いに少しでも役に立てば幸いです。