はじめに
こんにちは、Necoプロジェクトのsatです。本記事では分散ストレージCephのオーケストレータであり、Kubernetes上で動作するRookに関するものです。このRookに存在していたデータ破壊バグを我々が検出、修正した体験談、およびそこから得られたことを読者のみなさんに共有します。本記事は以前Kubernetes Meetup Tokyo #36におけるLTで述べた問題のフォローアップという位置づけです。
"解決までの流れ(詳細)"の節以外はRookやCephについて知らなくても適宜用語を説明するなどして読めるように書きました。
Rook/Ceph固有の話にも興味があるかたは以下の記事/スライドも併せてごらんください。
用語
Rook/Cephについて知らないかた向けに、まずは本節において出てくる用語を解説しておきます。
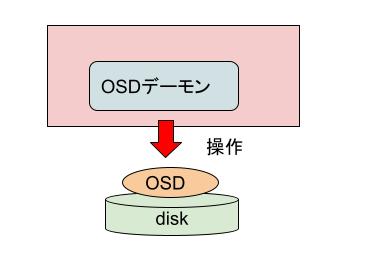
- OSD: ディスク1つに対して1個ないし数個存在するデータ構造。Cephは1つないし複数のノード上にあるOSDを束ねてストレージプールを作る。
- OSDデーモン: OSDを操作する常駐プロセス
- OSD Pod: 内部でOSDデーモンを動かすためのKubernetesのPod
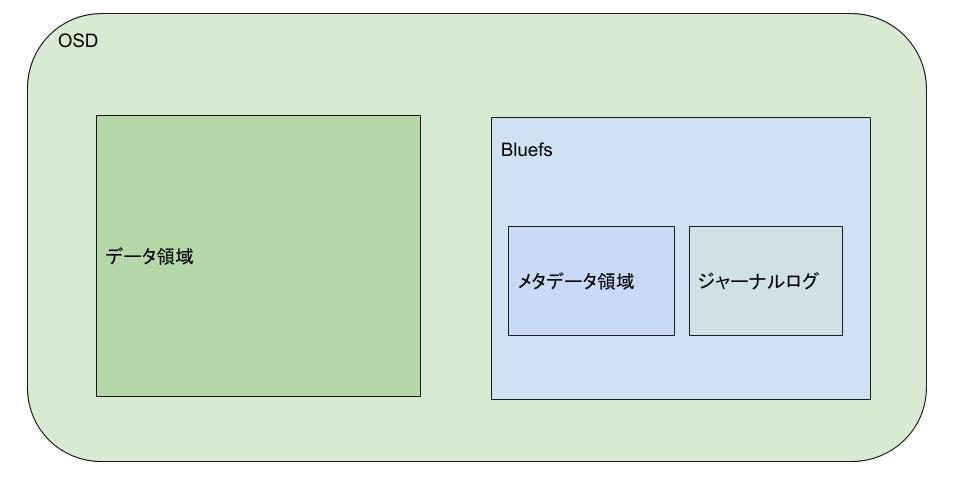
- OSDのデータ構造
- データ領域: ユーザデータを保存する
- bluefs: メタデータを保存するためのファイルシステム
- メタデータ領域: データ領域の中の個々のデータの位置やサイズなどの管理
- ジャーナルログ: bluefsの操作の整合性を保つためのログ
これらの関係を図示すると以下のようになります。

問題要旨
- 発生した問題: Cephのデータ保存領域であるOSDが壊れてアクセス不能になった
- 発生条件: 同じOSDに対応するOSD Podが2つ以上同時起動した場合
- 原因: OSDを扱うデーモンを動かすOSD Podの同時起動に対するRookの考慮漏れ
- 対処: Rookの修正によってOSDデーモンの同時起動を防ぐように排他制御した
解決までの流れ(概要)
調査および修正はおおよそ次のように進みました。
- 問題の検出: Kubernetesクラスタ、およびその上にRook/Cephクラスタを構築した開発環境の中のいくつかのノードにおいてメモリ不足になりOOM killerが繰り返し発生した。事象がおさまった後に当該ノード上のOSDがいくつか壊れていた
- 初期調査(1,2日程度): 問題発生時のログを調査した上でCephコミュニティ、およびRookコミュニティにissueを発行
- 本格調査(一か月程度): Cephコミュニティ上で開発者と共に調査。最終的に本来1つのOSDに対して1つしか起動してはいけないOSDデーモンが同時に2つ以上起動していた可能性を指摘される
- 根本原因調査(1,2日程度): OSDデーモンが同時起動したら同じ問題が起きること、OOM killerを契機にこの問題が起こりうることを確認
- 修正方針検討(3週間程度): RookとCephのどちらで直すべきかを2つのコミュニティをまたいで議論。最終的にRookにおいて修正することにした
- 修正(一か月程度): 修正作成、レビュー
合計すると3カ月弱という長期間を要しました。所要時間のうちの多くはupstream OSSコミュニティ上での議論に費やしましたが、このようなときに先走って手を動かしすぎると思わぬ手戻りが発生することがあるので、しっかりと合意をとるのが大事です。
もう一点。この問題は開発環境で起きたこと、発生頻度が低いこと、発生しても致命的な問題が起きないこと*1より、調査速度よりもRook/Cephの調査ノウハウ獲得を優先しました。これによってこの問題の対処以外の他の作業を止めずに余裕をもって調査を進められました。重大な問題だからといってなんでもかんでも最優先でやるべしというわけではなく、緊急度が低ければこのような対応をするほうがいいということもあります。
仮にこの問題が本番環境で起きていた場合はもっと急ぐ必要があるため、対処方法が変わってくるでしょう。たとえば原因究明後はupstreamコミュニティでの議論を待たずOSD Podを即座に独自修正版に更新し、upstreamにおいて修正が適用され次第そちらに差し替えるなどの対処が必要です。原因究明までの調査も短縮化の必要がありますが、今後似たような問題が起きた場合に、今回よりもはるかに高速に進められる知見を得られました。
解決までの流れ(詳細)
本節ではこの手の問題の検出から解決までの思考プロセスに感心があるかた、およびRookやCephのトラブル解析に興味があるかたに向けて、調査の詳細について記載します。興味がないかたは"おわりに"の節まで飛ばしてください。
問題の検出
最初に問題を検出したのは我々の開発環境でした。開発環境にはKubernetesクラスタ、およびその上にRook/Cephクラスタが構築されています。
あるとき、この環境上のいくつかのノードがメモリ不足に陥り、カーネルのOut-Of-Memory Killer(OOM killer)が繰り返し発生しました。この事象がおさまった後に当該ノード上に存在していたOSD Podのうちのいくつかが壊れていました。壊れたOSDはすぐに作り直したのですが、この事象が本番系で発生するとお客様のデータ損実につながります。データ損失は数ある問題の中でも最も重大なもののひとつなので、詳細調査をすることにしました。
初期調査
問題が発生したOSDに対応するOSD Podは、OOM killerのために再起動された後、initContainerの動作中にデータの不整合を検出して失敗し続けていました。
OSD Podのログを調査したところ、bluefs内のジャーナルログの再生に失敗していることがわかりました。
2020-10-28T02:07:55.499+0000 7f0aa7f1e0c0 -1 bluefs _check_new_allocations invalid extent 1: 0x7ae18a0000~10000: duplicate reference, ino 26 2020-10-28T02:07:55.500+0000 7f0aa7f1e0c0 -1 bluefs mount failed to replay log: (14) Bad address 2020-10-28T02:07:55.500+0000 7f0aa7f1e0c0 -1 bluestore(/var/lib/ceph/osd/ceph-9) _open_bluefs failed bluefs mount: (14) Bad address
続いて詳細な原因を確かめるため、bluefsのジャーナルログの中身を見ました。
2020-10-28T08:39:58.788+0000 7f79675c70c0 20 bluefs _replay 0x263000: op_file_remove 26 ... ★1 <中略> 2020-10-28T08:39:58.788+0000 7f79675c70c0 20 bluefs _replay 0x264000: op_file_update file(ino 32 size 0x1356 mtime 2020-10-27T23:10:42.988971+0000 allocated 10000 extents [1:0x7ae18a0000~10000]) ... ★2 <中略> 2020-10-28T08:39:58.788+0000 7f79675c70c0 -1 bluefs _check_new_allocations invalid extent 1: 0x7ae18a0000~10000: duplicate reference, ino 26 ... ★3
この結果、bluefsは次のような流れで壊れたことがわかりました。
- bluefs上のファイル(inode 26)を削除
- bluefs内の領域(extent) "0x7ae18a0000~10000" を別のファイル(inode 32)に割り当てた
- 上記extentは既に削除したはずのファイル(inode 26)に割り当て済みだったので不整合発生
もう一点、ファイル(inode 26)の最後の更新時刻(2020-10-23T08:29:44.981029+0000)は、それより一つ前のログが出力されたときの時刻(2020-10-28T08:39:58.788+0000)よりもはるかに古いこと、つまり時系列順に並ぶはずのログの時刻が逆転していることがわかりました。
本格調査
前節における調査の結果、なんらかの理由によってbluefsが壊れていることが明らかになったため、upstream OSSにissueを発行しました。このときはRookかCephか、いずれの問題かが明らかになっていなかったので、両方に対してissueを発行して、片方で進捗した場合はもう片方にも情報共有する、というやりかたにしました。
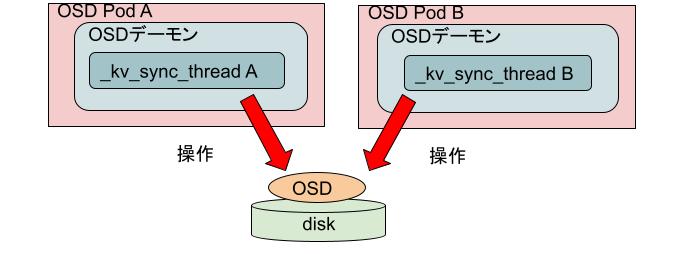
幸いにもCephのissueにおいてIgor FedotovさんというOSDについての豊富な知見をお持ちのかたがこのissueを見てくれることになりました。その後しばらく共同調査を進め、最終的にデバッグ情報を有効にした状態で採取したジャーナルログの調査によって、OSDデーモンの中に存在するジャーナルログを操作するための_kv_sync_threadというスレッドが複数存在していることが明らかになりました。以下ログの抜粋です。
2020-11-24T15:49:35.726+0000 7faf0eb7a700 10 bluestore(/var/lib/ceph/osd/ceph-0) _kv_sync_thread start ... ★1 <中略> 2020-11-24T15:50:01.624+0000 7f60bf7e4f40 0 set uid:gid to 167:167 (ceph:ceph) ... ★2 2020-11-24T15:50:01.624+0000 7f60bf7e4f40 0 ceph version 15.2.4 (7447c15c6ff58d7fce91843b705a268a1917325c) octopus (stable), process ceph-osd, pid 1 <中略> 2020-11-24T15:50:04.404+0000 7f60a9ad2700 10 bluestore(/var/lib/ceph/osd/ceph-0) _kv_sync_thread start ... ★3 <中略> 2020-11-24T15:50:05.828+0000 7faf0eb7a700 10 bluefs _flush 0x5562cd35f420 ignoring, length 25780 < min_flush_size 524288 ... ★ 4 <中略> 2020-11-24T15:50:05.828+0000 7f60a9ad2700 10 bluefs _flush 0x55c8422695e0 ignoring, length 14199 < min_flush_size 524288 ... ★5 2020-11-24T15:50:05.828+0000 7f60a9ad2700 10 bluefs _flush 0x55c8422695e0 ignoring, length 17245 < min_flush_size 524288 2020-11-24T15:50:05.828+0000 7faf0eb7a700 10 bluefs _fsync 0x5562cd35f420 file(ino 415 size 0x1e827 mtime 2020-11-24T15:50:05.829650+0000 allocated 20000 extents [1:0xa04a0000~20000]) ... ★6
ログから次のような事象が発生していたことが明らかになりました。
- OSDデーモンの中の_kv_sync_thread A(7faf0eb7a700)が起動
- 新しい別のOSDデーモン(7f60bf7e4f40)が起動。ここからがおかしい
- step1のものとは別の、恐らくはOSDデーモン(7f60bf7e4f40)の中のkv_sync_thread B(7f60a9ad2700)が起動
- _kv_sync_thread Aが動作
- _kv_sync_thread Bが再び動作
- また_kv_sync_thread Aが動作
こんなことが起きてしまったらbluefsが壊れるのは当然です。
根本原因調査
この問題が実際に発生していたことを確認するために、検証環境において次の2つのことを確認しました。
- OSD Podのレプリカ数が本来1であるところを2にすると、期待通りOSDは破壊され、かつ、OSDデーモンのログは問題を検出したときと同様なものになること
- 問題検出時と同様にOOM killerが発生したときに、Kubernetesの仕様上、同じ問題が起こりうること。具体的には以下の処理が繰り返し起きるときに同じOSDを操作するOSD Podが同時に2つ動作しうること
- ノード上で発生したOOM killerによるOSDデーモンの強制終了
- kubeletによるOSDデーモンの再生成
- ノードのメモリ不足に起因するOSD Podのeviction
OSD PodがStatefulSetによって管理されていれば上記のようなOSD Podの同時起動は起こりえないのですが、実際には様々な事情によりDeploymentによって管理されているためOSD Pod自体の同時起動は起きえます*2。しかしOSD Podの中にあるOSDデーモンの同時起動はCephがファイルロックによって防いでいるために、本来はこの問題は発生しないはずです。なぜこのようなことが発生してしまったのでしょうか。
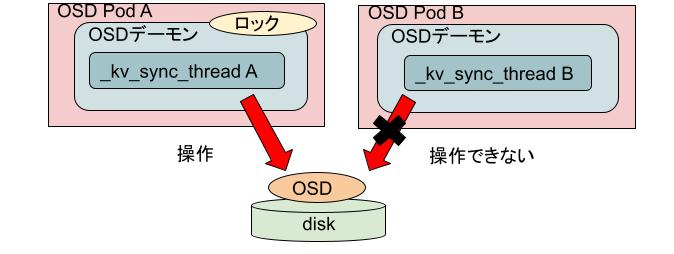
答えはファイルロックのありかが不適切だったことによります。Cephはロック用のファイルを"/var/lib/ceph/osd/ceph-
… containers: … command: - ceph-osd volumeMounts: - mountPath: /var/lib/ceph/osd/ceph-0 name: set1-data-0-xfvdg-bridge subPath: ceph-0 … volumes: … - emptyDir: medium: Memory # "/var/lib/ceph/osd/ceph-0"はメモリ上に存在 name: set1-data-0-xfvdg-bridge …
このため、複数のOSD Podが同時に動作した場合、それぞれ自身が持つメモリ上に存在する別々のロックファイルを獲得しようとして、常に獲得に成功してしまうという状況になっていました。
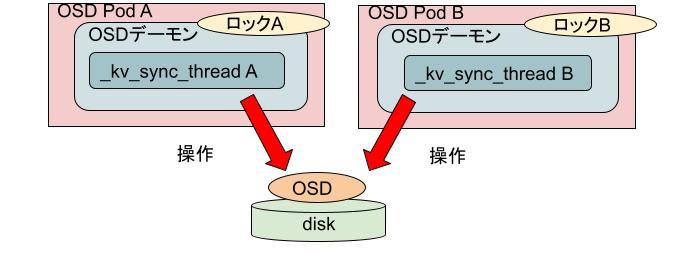
修正方針の検討
この問題を解決するもっとも単純な方法はRookに手を加えて以下のようにhostPathを使ってロックファイルを共有させることです。
volumes: … - hostPath: Path: /var/lib/rook/<OSDごとに固有のパス> name: set1-data-0-xfvdg-bridge …
ただしこの問題はRookのメンテナから反対を受けました。その理由は、安易にコンテナのデータを他のコンテナと共有すべきではない、可能な限りそのようなデータは少なくすべきだ、というものでした。OSDディレクトリ以下にはロック用のファイル以外にも多くのファイルが存在するために、それらのファイルも一緒に共有するのを嫌うのは無理からぬことです。彼はそのかわりにCephに手を入れてロックファイルだけをOSDディレクトリ以外の場所に置けるようにしてはどうかという提案をしました。
この提案をIgorさんにしたところ、技術的には可能であるが、そうするとアップグレード処理が複雑になること、他のツールにも修正が必要になりうることなどより難色を示されました。この答えをRookコミュニティに持ち帰った結果、最終的には不格好ではあるがデータが壊れるよりマシ、ということで上記のemptyDirをhostPathに変更する方法によって問題を修正することにしました。
修正
修正そのものは比較的シンプルだったために初期実装は簡単に終わりました。しかしながら影響範囲が大きかったこともあり、3週間にわたる綿密なレビューの末、ようやく修正がmasterブランチにマージされました。この修正はRook v1.5 branchにもバックポートされていて、近日リリースされるv1.5.6に取り込まれるはずです。
時間がかかって大変でしたが、見落としていた箇所が修正できたり、のちのちこのコードを見る人のためにコメントを追加したりと、最初に出したバージョンよりもはるかによいものになりました。
おわりに
本記事ではupstream OSSにおける複雑な問題に対処する際の以下のようなポイントを共有しました。
- 焦らずに関係者の合意をとった上で進めることが大事
- 所要時間のほとんどは実装ではなく議論に費やされる
- upstreamの修正を待たずに手元の環境に一時的に緊急修正をすべき場合もある
これらの情報が今後みなさまに何らかの形で役立つことを願います。
最後になりますが、この問題の解決に協力してくださったプロジェクトメンバ、Rookコミュニティのみなさま、およびCephコミュニティのみなさまに感謝いたします。