この記事は、CYBOZU SUMMER BLOG FES '24(クラウド基盤本部 Stage)DAY 16 の記事です。
こんにちは、Cloud Platformチームの竹村です。
私たちのチームでは、Necoと呼ばれるKubernetes基盤の開発や運用をしています。 このブログ記事では、大量の通信を行うアプリケーションをKubernetes上で運用する際に発生したネットワーク通信経路の障害に関してお話しします。
障害の概要
Kubernetes基盤を利用するチームから、クラスタ内のDNSサーバで性能問題が発生しているとの相談を受け、調査を開始しました。具体的には以下のような事象が起きていました。
- Pod内のアプリケーションから一秒間に数百リクエストの単位でクラスタ内のserviceの名前解決を行うと、
no such hostやi/o timeoutといったエラーが頻繁に発生する
障害の背景
はじめに障害の背景について説明します
DNSサーバ
私たちが運用しているKubernetesクラスタでは、目的別に2種類のDNSサーバを運用しています。
- node-dns
- 各ノードで動作するキャッシュDNSサーバ
- 権威ネームサーバからのDNSレコードの応答をキャッシュする
- ソフトウェアとしては、Unboundを使っている
- cluster-dns
- Kubernetesクラスタ内の権威ネームサーバ
- ソフトウェアとしては、CoreDNSを使っている
Pod内のアプリケーションがクラスタ内のserviceの名前解決を行う場合のフローは以下の通りです。
- アプリケーションからnode-dnsに問い合わせを行う
- node-dnsにキャッシュがある場合は、node-dnsが応答を返す
- node-dnsにキャッシュがない場合は、node-dnsがcluster-dnsに問い合わせを行う
- cluster-dnsがnode-dnsに応答を返す
- node-dnsがアプリケーションに対して応答を返し、node-dnsはDNSレコードの応答をキャッシュする
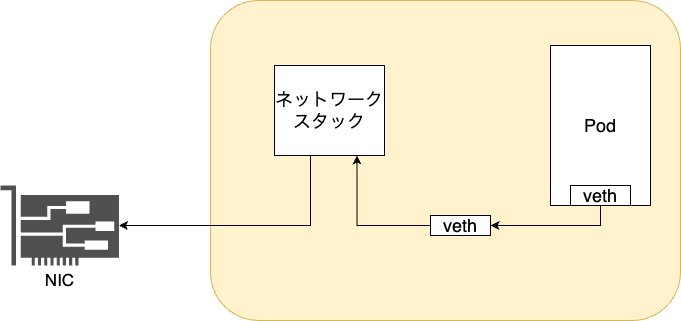
Kuberentes基盤のネットワーク構成
Kubernetes基盤のネットワークとしては、主にCiliumを使用しています。
どのようにCiliumを運用しているかは、CYBOZU SUMMER BLOG FES '24(クラウド基盤本部 Stage)DAY 17の記事で紹介される予定です。
Podからの送信パケットはvethインターフェースを通り、Linuxカーネルのネットワークスタックで処理されて、NICへ渡されます。
私たちのKubernetesクラスタでは、一部の用途を除きオーバーレイネットワークは使っていません。
エラーが起きていたアプリケーション
名前解決のエラーが発生していたアプリケーションは、MySQLクラスタを監視するものでした。このアプリケーションは、毎秒MySQLクラスタへ接続し、SQLクエリを実行します。SQLクエリが正常に実行できているかを確認し、クラスタが正常に動作しているかを確認します。アプリケーションは毎秒ごとにセッションを再作成しています。 今回は、アプリケーションが監視するMySQLクラスタの数が増えた後から、頻繁に名前解決のエラーが発生するようになっていました。
障害調査
DNSサーバの調査
まず、node-dnsやcluster-dnsに性能問題があるかを確認するため、メトリクスやログを調査しました。その結果、以下のことがわかりました。
- node-dns、cluster-dnsは正常にリクエストを捌けている
- 存在しているドメインに対しては、NXDOMAINを返していない
これらの結果から、node-dnsとcluster-dnsに性能問題はなさそうだということがわかりました。
一方で、node-dnsのログを確認した際に気になることがありました。それは、node-dnsにアプリケーションからの名前解決のリクエストが記録されていなかったことです。そして、node-dnsにクエリが記録されていなかったタイミングで、アプリケーションで名前解決のタイムアウトのエラーが発生していました。また、他の時間帯のログでも同様のことが起きていることが確認できました。
この調査結果から、アプリケーションとnode-dns間の通信経路のどこかで名前解決のパケットが失われている可能性があることがわかりました。そのため、次にネットワークの調査を行いました。
# ドメインは架空のもので実際に使われているものではありません
# アプリケーション側のログ
{
"severity":"ERROR",
"logged_at":"2024-06-08T23:30:11.972Z",
"message":"write check failed","target":"moco-1",
"error":"ping failed: dial tcp: lookup moco-1: i/o timeout",
}
# node-dnsのログ
Jun 08 23:30:01 unbound[1:1] info: 192.0.2.15 moco-1.default.svc.cluster.local. A IN NOERROR 0.000000 1 152
# 次のログが出てくるまでに10秒程度あいている
Jun 08 23:30:12 unbound[1:1] info: 192.0.2.15 moco-1.default.svc.cluster.local. A IN NOERROR 0.000000 1 152
ネットワークの調査
まず、コンテナに関するメトリクスでパケットドロップが発生しているかを確認するために、cadvisorの以下のメトリクスを確認しました。
container_network_transmit_packets_dropped_total- 送信中にドロップされたパケットの数を示すメトリクス
- 1秒間で100個ほど送信中にパケットがドロップされていた

この結果より、Podからの送信パケットが何らかの理由でドロップされていることがわかりました。
また、Node exporterのnode_softnet_dropped_totalのメトリクスを確認したところ、こちらのメトリクスも増えていることがわかりました。

node_softnet_dropped_totalは、カーネルがパケットをCPUのbacklogキューにエンキューする際に、backlogキューが満杯でエンキュー出来ずパケットがドロップされたことを示しています。このことから、パケットがどの部分でドロップされているかは特定することはできました。一方で、パケットが通っているどの部分で、backlogキューに入れられているかはわかっていませんでした。そこで、backlogキューに関してのドキュメントやLinuxのソースコードを読むことで、障害の原因を解明することができました。
障害の原因
今回の障害ではbacklogキューが満杯になったことで、Podからの送信パケットがドロップされていました。また、送信パケットがドロップされたことで、名前解決のパケットがドロップされ、アプリケーション側で名前解決のエラーが起きていました。
パケットドロップが起きていた原因としては、アプリケーションが大量にパケットの送受信を行なっていたからでした。具体的には、1Podから1秒間に1万5千パケット程度送信されていました。
Podから別のPodやホストへの通信は、以下のような経路で処理されます。
- Podから送信されたパケットは、Podにアタッチされているveth インターフェースに渡される
- bakclogキューに入れられる
- backlogキューが満杯の場合はパケットはドロップされる
- backlogキューに追加されたパケットの処理が行われる
- ホスト側のvethインターフェースにパケットが渡される

今回はこの2番目のbacklogキューにパケットをエンキューする際に、backlogキューが満杯で、パケットがドロップされていました。backlogキューの長さは、カーネルパラメータのnet.core.netdev_max_backlogによって決まります。Kubernetesノードのカーネルパラメータの値を確認したところ、net.core.netdev_max_backlogはデフォルトの 1000になっていました。このため、大量にパケットを送信するPodがノードに乗ったことで、このbacklogキューが満杯になり、パケットドロップが発生していたと考えられます。
Kubernetes上でアプリケーションがmoco-1というserviceの名前解決を行うと、以下の5つのクエリが実行されます。
moco-1.default.svc.cluster.localmoco-1.svc.cluster.localmoco-1.cluster.localmoco-1.localmoco-1.
今回はパケットドロップにより、以下の現象が起きていたと考えられます。
no such hostが返ってくるパターン
moco-1.default.svc.cluster.localのクエリのパケットがドロップされる。他のクエリのパケットは全てnode-dnsに到達した場合、moco-1.svc.cluster.localといったレコードは存在しないため、node-dnsからNXDOMAINが返される。アプリケーションはNXDOMAINが返されたので、ドメインは存在しないと判断して、no such hostというエラーを返す。
# no such hostが返ってくるパターン
moco-1.default.svc.cluster.local パケットがドロップされて、node-dnsに到達しない
moco-1.svc.cluster.local NXDOMAINが返される
moco-1.cluster.local NXDOMAINが返される
moco-1.local NXDOMAINが返される
moco-1. NXDOMAINが返される
i/o timeoutが返ってくるパターン
すべてのクエリのパケットがドロップされたことで、node-dnsに全てのパケットが到達しない。アプリケーションは一定時間DNSサーバから応答がないので、i/o timeoutとしてエラーを返す。
# i/o timeoutが返ってくるパターン
moco-1.default.svc.cluster.local パケットがドロップされて、node-dnsに到達しない
moco-1.svc.cluster.local パケットがドロップされて、node-dnsに到達しない
moco-1.cluster.local パケットがドロップされて、node-dnsに到達しない
moco-1.local パケットがドロップされて、node-dnsに到達しない
moco-1. パケットがドロップされて、node-dnsに到達しない
障害の再現
backlogキューが満杯になりパケットがドロップされているかを確認するために、dctestを用いて再現実験を行いました。dctestとは、VMを使ってデータセンター構成を丸ごと仮想化した環境で、その環境上でKubernetesクラスタが動作しています。 dctestに関しての詳しい説明に関してはこちらのスライドをご参照ください。
まず、今回の障害と同じぐらいの頻度でパケットを送信するプログラムをGo言語で実装しました。
次に、dctest環境にこのプログラムをデプロイしました。このプログラムを1時間ほど動かして、/proc/net/softnet_statのメトリクスを確認したところ、パケットのドロップが起きていることが確認できました。
一番右の列がCPUのコア数を示しており、一番左からパケットの処理数、ドロップされたパケット数を表しています。今回の結果では、CPUのコア8、9で790、183個のパケットがドロップされていました。
$ awk '{for (i=1; i<=NF; i++) printf strtonum("0x" $i) (i==NF?"\n":" ")}' /proc/net/softnet_stat | column -t
16988709 790 14083 0 0 0 0 0 0 0 0 0 8
16356210 183 12394 0 0 0 0 0 0 0 0 0 9
パケットがドロップされる現象を再現できたため、次にパケットのドロップ理由を調査しました。
こちらの記事を参考に、Linuxのperfコマンドを用いてパケットのドロップ理由を取得しました。
perfコマンドを実行してパケットのドロップ理由を確認したところ、CPU_BACKLOGが理由でパケットがドロップされていることが確認できました。
# 対象のPodのcgroupのパスを取得する
$ sudo crictl inspect <container_id> | jq .info.runtimeSpec.linux.cgroupsPath
$ POD_CGROUP="kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pode4d11b28_51cc_406d_a08a_dc54df2777e1.slice"
# 対象のPodでパケットのドロップ理由を取得する
$ perf record -e skb:kfree_skb --cgroup $POD_CGROUP -a -- sleep 1800
^C[ perf record: Woken up 36 times to write data ]
[ perf record: Captured and wrote 10.952 MB perf.data (7139 samples) ]
$ perf script
dnsbench 616472 [002] 29235.662288: skb:kfree_skb: skbaddr=0xffff8a37cda3e500 protocol=2048 location=0xffffffff936a6d18 reason: CPU_BACKLOG
dnsbench 616472 [002] 29235.662323: skb:kfree_skb: skbaddr=0xffff8a37cda3e500 protocol=2048 location=0xffffffff936a6d18 reason: CPU_BACKLOG
CPU_BACKLOGの説明を読むと、backlogキューが満杯かRPS flow limitによってパケットのドロップが起きると説明されています。私たちの環境だとRPS flow limitは無効になっているため、backlog キューが満杯でパケットがドロップされていたことを、改めて確認することができました。
@SKB_DROP_REASON_CPU_BACKLOG: failed to enqueue the skb to the per CPU backlog queue. This can be caused by backlog queue full (see netdev_max_backlog in net.rst) or RPS flow limit
https://elixir.bootlin.com/linux/v6.1.9/source/include/net/dropreason.h#L234
障害の対策の実施
今回の障害の対応としては以下の対応をしました。
netdev_max_backlogの値を増やす- softnetに関するアラートを設定する
- softnetに関するアラートのRunbookの整備
これらの対応により、今回と同様の障害が起きにくくなり、同様の障害が起きた際に早期に気付けるようになりました。ただし、netdev_max_backlogの値を増やすといった対応は根本的な対策ではありません。今後、より多くのパケットを送信するPodがデプロイされた場合、再びbacklogキューが満杯になりパケットドロップが起きてしまう可能性があります。
根本的な対策としては、Ciliumの最新の機能であるnetkitを利用することが考えられます。netkitはLinuxカーネル6.7で導入されたBPFプログラムを1つ以上アタッチすることが可能な仮想的なネットワークデバイスです。
vethインターフェースをnetkitインターフェースで置き換えることで、Podからの送信パケットがbacklogキューを経由せずに、物理デバイスに直接リダイレクトできるようになります。この機能はCiliumの1.16から利用できます。私たちのチームではCiliumを使用しているので、今後はnetkitの検証を行なっていきたいと考えています。
参考文献
- https://eng-blog.iij.ad.jp/archives/18147
- https://arthurchiao.art/blog/linux-net-stack-implementation-rx-zh/
- https://blog.packagecloud.io/monitoring-tuning-linux-networking-stack-receiving-data
- Lei, Jiaxin, Manish Munikar, Kun Suo, Hui Lu, and Jia Rao. 2021. “Parallelizing Packet Processing in Container Overlay Networks.” In Proceedings of the Sixteenth European Conference on Computer Systems, 261–76. EuroSys ’21. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3447786.3456241
- https://archive.fosdem.org/2023/schedule/event/meta_netdevices/attachments/slides/5971/export/events/attachments/meta_netdevices/slides/5971/meta_netdevices.pdf