@ymmt2005 こと山本泰宇です。短い夏休みから帰ってきました。
今回は cybozu.com のデータセンターで運用を開始した自動障害回復システム「月読」を紹介します。障害にも色々ありますが、今回紹介するのは仮想マシンのホストサーバーの物理障害を検出して、稼働していた仮想マシンを予備のホストに移動する仕組みです。
月読は、データセンター全域に分散したエージェントが協調動作するピア・ツー・ピア (P2P)システムとして作られています。以下分散システムの話題が多数でてきますが、とても難解というわけではないので、分散システムの入門記事としてお楽しみください。
障害にどう対処するか
物理障害対策の基本は二重化(多重化)です。アプリケーションサーバーのようにデータを持たないサーバーであれば active-active 構成で、データベースサーバーのようにデータを持つのであれば active-standby 構成で組むことが多いでしょう。
ところが、世の中にはこの典型的な冗長化を許さないソフトウェアもあります。一つの例がサイボウズ Office です。ローカルファイルをプログラムが直接利用する仕組みであるため、冗長化が困難なのです。このような場合は、SAN などのネットワーク共有ストレージを導入し、プログラムとストレージを分離して対応します。
こうした背景から、cybozu.com では Square という自社製の高可用ストレージシステムを開発して利用しています。Square はストレージサーバーを複数台使って耐障害性を高めています。
残るプログラム部分については、仮想マシン(VM, Virtual Machine)で動作させることにしました。プログラム毎に異なる環境やリソースの調整が容易になるためです。加えて、ホストサーバーに障害が発生した際は、仮想マシンを予備のホストに移動すればサービスを簡単に復旧できます。
図にすると以下のようなシステム構成でサーバー数百台が稼働しています(クリックで拡大)。 なお、ネットワーク機材は完全に二重化されています。

障害対応の自動化
cybozu.com のシステムで仮想マシンのホストサーバーが故障した場合、以下の手順をこなして復旧させなければいけません。
- 障害の検知
- 障害原因が仮想マシンホストサーバーの故障であることを確認
- 壊れたサーバーの電源を切る
- 予備のホストサーバーから一台、復旧用のサーバーを選択
- 故障したホスト上の仮想マシンを復旧用サーバーに移動
- 仮想マシン上で稼働するべきプログラム類の起動
つい最近まで、この手順はモニタリングシステムが障害を検出した後にオペレーターが手動で実施していました。一つ一つ確認しながら作業すると、復旧までに 30 分以上かかってしまい、稼働率を下げてしまう要因になっていました。
サーバー台数が増加するにつれて故障発生の機会も増加します。稼働率を維持するため、またオペレーターの安眠を守るために、この作業を自動化することにしました。余談ですが、月読は安眠が守られるよう願いを込めて名付けたものです。
設計のポイント
自動で障害に対応する場合、注意をしなければいけないことがいくつかあります。 それぞれ月読でどうしているかを解説します。
誤検出の防止
監視側の機材の故障を、監視対象の機材の故障と取り違えると酷いことになります。多少の応答の遅れや再接続を故障とみなしてしまうのも、酷いことになるでしょう。
月読では必ず複数のサーバーで監視する仕組みにしました。監視サーバーのうち一台が故障を検出しても、他のサーバーが検出しなければ誤検出とみなして、検出の精度を上げるわけです。
スプリットブレインの防止
故障したかに見えたサーバーが実はまだ動作していたりすると、恐しいことが起きます。息の根が確実に止まっていることを保証してやらねばなりません。
cybozu.com の全機材には OS とは別に、ハードウェアの電源を遠隔から操作する「遠隔管理システム」が搭載されています。月読はこの遠隔管理システムを利用して確実に故障サーバーの電源を落とすことで、スプリットブレインを防止しています。
この仕組みに加え、Square にも同一のボリュームを同時に複数のサーバーが利用することができないスプリットブレイン防止機構が備わっています。
連鎖障害の防止
自動障害回復システムの不具合は、多数のサーバーを連鎖的にダウンさせてしまいかねません。事実、Amazon や Google でも管理システムの不具合が原因で大規模障害を起こしています(1, 2)。
月読は短期間に多数のサーバーの故障を検知すると、自動での障害回復を諦めてオペレーターに緊急警告を投げ続けるよう設計してあります。
つまり月読は、(1)多数のサーバー間で相互監視して、(2)障害の検出には何らかの合意(consensus)を必要とします。
現時点で既にサーバーは数百台あることから、相互監視の対象を手作業で設定することは避け、プログラムが自律的に監視対象を見つけることにします。つまり、ピア同士が自律的に相手をみつける自律分散システムとします。
合意の形成は真面目にやるなら Paxos のような分散ステートマシンを持ち出すところですが、障害の検出程度なのでシンプルに特定のサーバーに情報を集約して判断させることにしました。この特定のサーバーの故障には active-slave 構成で冗長化して備えることにします。
図にすると以下のようなイメージです(クリックで拡大)。

仮想マシンも含め、全てのサーバー上で月読のエージェントが動作していますが、仮想マシンはそのホストサーバーで動作している月読だけに接続します。ホストマシンと同時に死んでしまう仮想マシンは、物理障害の監視には適さないからです。
エージェント間通信
自律的に通信相手を探して確実に情報を交換するには、(1)通信相手を発見して接続し、(2)並の障害は乗り越えて情報を伝達する仕組みが必要です。結論から言うと、月読はネットワークの情報をもとにランダムにピアを選択し、情報の交換はゴシップ・プロトコルで行います。
通信相手の発見
インターネット P2P ではピアの発見は難しい問題ですが、データセンター内の P2P ではネットワークやホストの一覧が利用できます。この情報を利用してランダムにピアを選択して接続することができます。
ゴシップ
いつどのような障害が発生するか分からない分散環境で、確実にデータを伝達する方法は多くはありません。月読ではゴシップ・プロトコルという仕組みで、データを定期的に交換しあうことで一時的な通信障害があっても確実に情報を伝達させています。
ゴシップは有効期限や伝達範囲などの属性を持たせたデータです。月読は新たなゴシップを受け取ると内部でイベントが発生し、任意の処理を実行させることができる仕組みを備えています。
ネットワークの分断対策
ランダムに組まれたネットワークでは、運が悪いと一部のエージェントが分断されてしまうことがあります。
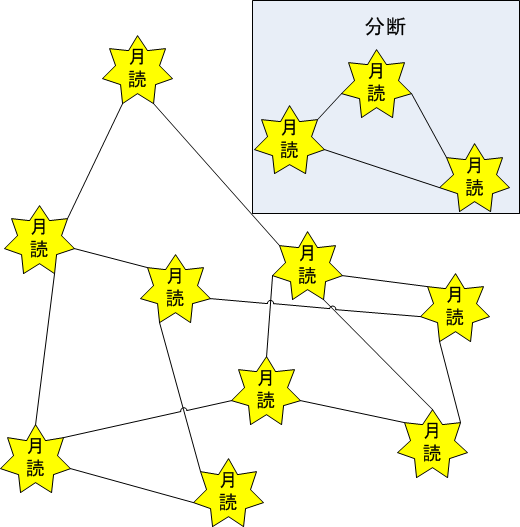
月読は分断を検出するために、ある特定の(冗長化された)サーバーで動作するエージェントから一定の間隔でゴシップを流しています。このゴシップが一定時間更新されない場合、そのエージェントは分断されたネットワークにいるものと判断して、ピアとの接続を切り、ランダムに選び直したピアに再接続します。
障害の検出と回復
月読のピアは、接続しているピアに一定間隔でゴシップを送ります。これを利用するとピアの障害を検出できます。
まず、ゴシップを送ると先方から TCP RST が飛ぶ場合があります。これは月読のプログラムが停止したことを通常は意味します。障害かもしれませんし、ちょっと再起動したのかもしれません。
先方が完全に停止している場合、ネットワークスイッチから ICMP Destination Unreachable が来る場合もあります。
でも経験上もっとも多いのは、単に黙ってしまう障害です。何の返事もないまま、パケットが捨てられてしまうのです。この状態を検出するには、受け取った相手のプログラムが返事を返すようにすれば良いです。が、月読ではその必要はありません。
月読のピアは一定間隔でゴシップを送りあうのですから、一定の時間ゴシップを寄越さないピアは死んでいるとみなすことができるのです。
検出したピアの障害情報は、ある特定の(冗長化された)サーバーに通知します。ゴシップで通知しても良かったのですが、迅速な処理を行いたかったので別の方法で通知しています。詳細は割愛します。
通知を受け取ったサーバーは、一定数以上のエージェントが障害と判定した場合にのみ、該当のサーバーが真に故障したと判定します。故障した機材が仮想マシンのホストサーバーである場合、先述の手順で仮想マシンを予備サーバーに移動して復旧します。
結果として、もろもろ含めて障害発生から 3 分から 5 分程度で自動的に復旧できるようになりました。
その他の機能
延々ピア・ツー・ピアの話をしてきましたが、月読は P2P のプログラムというわけではありません。実は、月読は複数のネットワークプロトコルをプラグインで自由に拡張できる汎用サーバープログラムで、P2P 機能は一つのプラグインに過ぎません。
故障の判定や故障からの自動回復も、プラグインとして実装されています。
他の機能として、任意のノードを自由に接続して通信ができる特徴を利用した大容量のファイルを高速にバケツリレー方式で転送する機能などが実装されています。

まとめ
cybozu.com のハードウェア障害を自動的に復旧する月読というシステムを紹介しました。
月読は P2P 技術をデータセンター内で利用して自律動作するので、オペレーションコストがかかりません。障害の誤検知や暴走時の対処があらかじめ考慮されているため、大規模な障害を引き起こさないようになっています。
本質的には、月読はプラグインで拡張可能な汎用ネットワークサーバーです。障害回復以外にも高速にファイルを転送する機能などが実装されています。
なんでもはお答えできませんが、ご質問があれば twitter でお願いします。