こんにちは、Hazama チームの萩原(@hagifoo)です。
ハードウェアは故障し、ソフトウェアにはバグがあり、運用ではミスがおきるもの。もちろん、障害が発生しないのが理想ですが人間が作ったものに完璧はありません。そこで、障害の前兆や発生を捉え、その詳細を運用チームに知らせるための監視システムが必要となります。cybozu.com でも以下のようにありとあらゆるものを監視するシステムを構築し日夜監視を行なっています。
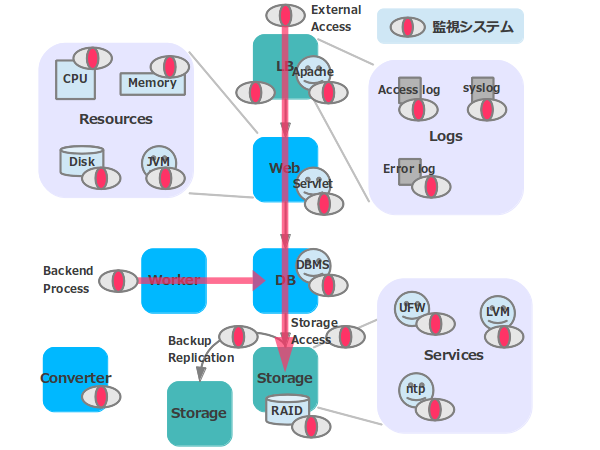
今回は、そんな cybozu.com の監視(モニタリング)システムについてお話しします。
cybozu.com と障害
まずは、監視対象である cybzou.com について説明します。
cybozu.com は大まかに以下のような構成になっています。
- ロードバランサ
- Web サーバ(VM)
- DB サーバ(VM)
- ストレージサーバ
- 非同期処理ワーカー(VM)

DB サーバのボリュームは複数のストレージに保存され冗長化されています。この構成に複数のお客様が同居するマルチテナント環境となっています。
※実際には上記の構成が幾つも存在しています。
冗長化により簡単にはダウンしないように作られていますが、それでも過去様々な障害が発生しアクセス遅延、アクセス断につながってしまいました。代表的な障害を紹介します。
ハードウェア故障による VM ホストのダウン
最近多いのはこの手のハードウェア故障です。台数が増えてくると必然的に多くなっていくため、サービスの発展とともに増えてきました。 Web や DB などの VM ホストが故障すると、上に載っている VM が軒並み落ちてしまうのでアクセス断になる確率が高いです(これを避けるために冗長化されている VM は別ホストに分散されています)。 今は自動障害回復システム月読のおかげで数分のうちに自動復旧できるようになっています。
JVM の thread が暴走してメモリ枯渇
マルチテナント環境で怖いのはこの手のリソース枯渇です。特にメモリ枯渇の場合は full GC が頻発して、全てのお客様に影響がでてしまいます。アクセス自体ができなくなれば LB から自動で切り離されるためお客様にはほぼ影響ありませんが、中途半端に繋がる状態だとお客様のアクセス遅延、アクセス断を引き起こしてしまいます。
監視システムの設計
では、どのように監視システムを設計すればよいのでしょうか?
最初に考えるべきは SLT(Service Level Targets) で決められたサービス稼働目標です。達成すべき目標がないならそもそも監視をする必要がありません(は言い過ぎですが)。
次に、その目標を達成できたかどうかを定量的に評価するための監視、つまりサービスが稼働しているかどうか=障害とはなにかを規定するための監視を設定します。そして、サービス稼働のために必要となる対象(サーバー、デーモン etc)を漏れがないように分類し監視システム全体を設計、開発していくことになります。
また、個々の監視サービスを設計する上でObject, Method, Subject, Alertの 4 つを考えなくてはなりません。

このように SLT からブレークダウンして、システム全体を設計することで漏れのない監視を実現することができます。
また、監視というと「とにかく監視すればいいだろう」と考えがちですがそれだけではいけません。もうひとつの重要なこと、それは 間違って障害を検知しないこと です。「オオカミ少年」の話を思い出していただければ分かると思いますが、10回に9回は嘘の警告を鳴らすシステムがあったら...。誤検知はシステムの信頼性を下げ、運用チームに無駄な負担を強いるため、監視の効率を損ねてしまいます。残念ながら初期の頃の監視システムは誤検知が多く、色々と迷惑をかけてしまいました。
最初からちょうどいいところを目指すのは難しいので、いったん監視システムを作ったら恒常的に見直しを行なっていくことが大事ですね。
3つの監視
では cybozu.com ではどのように監視を実現しているのでしょうか?我々は以下の 3 種類の監視を組み合わせることで漏れのない障害検知を目指しています。
- 外形監視
- 症状監視・リソース監視
- ログ監視

外形監視
外形監視は cybozu.com の障害を規定する監視です。
外部から(実際には .com 内部から一旦外に出て)サービスの監視用 API を叩き、1 秒以内にレスポンスがあることを確認しています。Web サーバーにアクセスできるかどうかを確認するだけだと、それ以降の永続化に関わる部分に触れないため、毎回書き込みまで行なって導線が問題ないことも担保します。
以前はこの監視が 10 秒連続で失敗した場合を障害と判断し警告を飛ばしていました。しかし、複数の WEB サーバーにロードバランシングしているため、そのうち一台で「アクセスはできるけれど応答がない」という障害が発生した場合に、「1/n の割合でリクエストに失敗する」という状態になってしまい障害を見逃したことがありました。
そのため、現在は
- 60 秒のウインドウ中で
- ある程度以上の割合で失敗している状態が
- 10 秒続いたら
障害とみなす、というロジックになっています。
※「ある程度の割合」は LB や設定によっても変わるのでチューニングが必要です
上記以外にもバックエンドの処理や、お客様データのバックアップ、レプリケーション、オンプレミスデータの移行なども外形監視の対象となっています。 バックグラウンド処理は非常に時間がかかる場合があるため、処理が遅延、もしくは止まっているのか、それともただ長いだけなのかの判断が難しい場合があり苦しめられました。
症状監視・リソース監視
症状監視・リソース監視は各サーバーや JVM などの状態を定期的に監視、記録し値や変化率がしきい値を超えた場合に警告を飛ばします。また、記録から障害原因を特定するのにも役立ちます。
cybzou.com では zabbix を利用することで症状監視・リソース監視を行なっています。このあたりの話はゴロゴロ転がっていると思うので割愛します。
ログ監視
ソフトウェアのログに対する監視です。障害の予兆を発見したり内部の動きを知るためには必須ですが、基本文字列なので自動解析が難しいです。
cybozu.com では Apache のアクセスログをセミリアルタイムに解析するようにしており、500 系のエラーが一定の割合を超えた場合に警告を送るようにしています。前述の外形監視は特性上、個別のお客様に発生する障害(DB ロックなど)を発見できないため、組み合わせることでお客様がエラーが多いな、と感じるのとほぼ同時に対応を始めることができます。
Apache 以外にも大量にソフトウェアのログは出力されていますが、現状は自動的な解析まで手が回っておらず人の目が頼りになってしまっています。 1年以内には fluentd や Heka のようなログ収集ツールと機会学習を組み合わせて自動的にアラートを上げるシステムを構築していきたいと考えています。
その他の監視
ここまではお客様への機能提供に直接関わる部分の監視でしたが、それ以外にも間接的に cybozu.com を支えているサービスの監視も欠かせません。ntp や自動復旧システムなどインフラを支えるサービスも同様に監視を行なっています。
モニタリングフレームワーク
ここまで説明してきた監視には実際に運用する上で色々と気をつけた方がいいことがあります。インフラチームではそういった面倒をまとめてみてくれるためのフレームワークを用意しています。
安定的に監視したい
監視プロセスはしばしば固まることがあります。実際、SSL 通信や I/O 中に無期限に停止していたことがありました。 安定した監視のために、フレームワークでは子プロセスで監視をし、停止している子プロセスは再起動するようになっています。
緊急警告手段を統一したい
緊急時の警告は、一系統では不安なので二系統以上で通知するようにしています。 そのような警告手段をばらばらに実装するのは無駄なので、フレームワークで警告を送信する仕組みを提供しています。
警告はまとめて送ってほしい
警告メールが大量に来ると見づらい上に状況が把握しづらいので、同じ障害の警告をまとめて一つのメールで送るようにしています。
一度送ったら後はたまにでいい
一度障害を確認した後は、基本人間による監視が始まるため、警告メールが送られてきても無駄なだけです。 そのため、障害継続中かどうかを確認できる程度の頻度に落とします。
警告を抑制したい時もある
意外と面倒なのが警告の抑制です。警告が飛んできても何もできない場合(そういう時もあるのです)やメンテナンス中などは警告を抑制する必要があります。大域的な抑制はフレームワーク側でやってくれるため警告の切り忘れが防げますが、現状細かい制御ができないので設計する際はここも考えておくのが良いと思います。
最近はモニタリングデーモンが増えてきたこともあり、色々と管理が面倒になってきていたのですが、新人の野島さんが一括管理のためのツールを作ってくれたので大分楽になりました。もっと早い段階で、こういうシステムを織り込んでおけばよかったと反省しています。
誰が監視者を監視するのか?
「最近警告が来ないなぁと思っていたら、監視システムが死んでたよw」では笑い話にもなりませんが、監視システム自体の監視は欠かせません。たまたま障害と重なりませんでしたが、監視システムのうちの一つが動いていないことが過去にありました。
cybozu.com のモニタリングデーモンは upstart によって制御されているため、今はこの仕組みを上手く使うことで「監視者の監視」を行なっています。 以下のような start on の条件を入れることで、他のジョブが予期せず停止した場合にのみ起動するタスクを作成することができます。 後はこのタスクから警告を飛ばしてあげれば、モニタリングデーモンの死活監視を簡単に行うことができます。
description "my-monitor"
start on stopped RESULT=failed JOB=my-monitor
task
...
完璧な監視システムのまとめ
cybozu.com では今日も有象無象の障害が発生していますが、監視システムのおかげで 99.9% 以上の稼働率を達成することができています。ただ、どんなシステムにも必ず欠点はあるものです。完璧な監視システムを作るただ一つの手段は、障害を見落としたら検出できるようにしたり、誤警告が多ければ精度を上げるといった、絶え間ない改善に尽きます。
cybozu.com にはインフラ専門の開発部隊(Hazama チーム)が置かれており、監視システムを改善し続ける体制となっています。機会があれば、モニタリングフレームワークのオープンソース化も検討したいと思っています。ご意見あれば、@hagifoo までお願いします!