サイボウズ・ラボの光成です。
今回は原因究明に半年以上かかったバグ調査の紹介をいたします。
弊社はクラウドサービスcybozu.comを提供しています。 クラウドサービスでは障害対策のためのデータバックアップやレプリケーションが必須です。 現在ラボの星野がメイン、私はサブとして弊社サービスでの利用を目指した次期バックアップシステムWalB(GitHub)を開発しています。
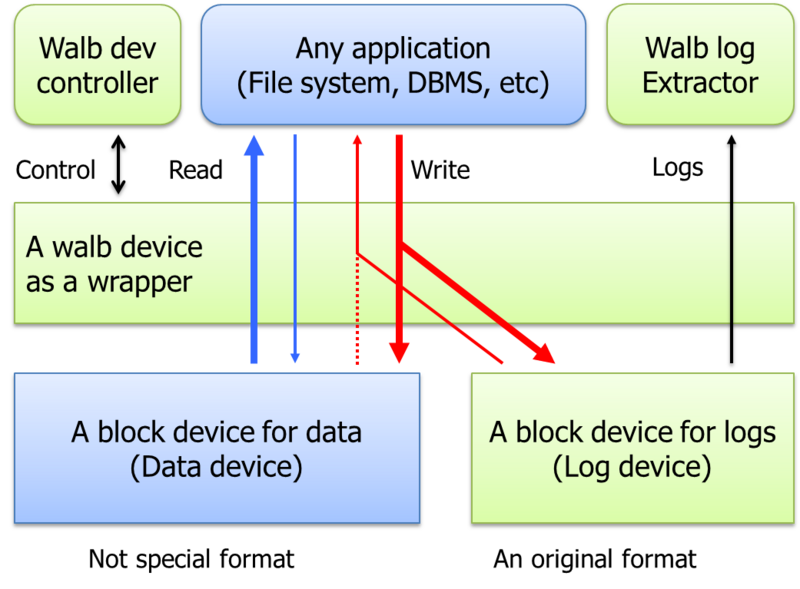
WalBは、ファイルシステムとdiskの間に入ってIOを全て記録するブロックデバイスとIOのログを管理するツールからなるシステムです。
詳細はリンク先をごらんください。
発端
去年はラボ内の開発環境でテストを進め、本社でテスト運用を開始するのが目標でした。 ところがラボでテストを開始して4カ月後の2015年4月、不正なlogpackが検出されました。 logpackとはWalBで用いられるデータフォーマットの一つです。 ログをみるとlogpackが壊れていたのでしばらくreadをリトライし、正常に読めたためシステムは継続していました。
このエラーは一度発生しただけで、かつ致命的なものではなかったのでしばらく様子を見ることにしました。 すると20日後ぐらいに再度エラーが報告されます。
これはきちんと原因追求しないといけないということで、WalB kernel driverのレビューをやり直したり、チェックコードを入れたりしました。 しかしエラーが20日に一度ぐらいしか起きないのでなかなか進展しません。
エラーの再現頻度を上げる
(試行錯誤があったのですが省略)その後8月の中頃に、データの読み書き頻度を調整することでエラーの再現頻度をあげるチェッカーツールwldev-checkerを作ります。
wldev-checkerを用いると最短で10分に一度でエラーが発生するようになり、現象を追跡しやすくなりました。 ただ数時間走らせてもエラーがでないことがあります。 現象の違いを調べることでデータflush周りに何か問題がある可能性が高くなりました。
再度WalB driverを調べたところキャッシュ制御に関わるフラグREQ_FLUSHとREQ_FUA(Explicit volatile write back cache control)の扱いにミスがあったことに気づきます。 そのあたりを修正することでwldev-checkerでもエラーがでなくなりました。
問題解決…と思ったら
これで解決したかと思われたのですが、数日後またもやエラーが報告されます。 ただ今度はチェッカーツールを用いても約3日に一度しか再現しません。 diskへの書き込みと同時にメモリにも出力する仮想ブロックデバイスを作成したり、driverのチェックコードを強化したりしますがなかなか特定にいたりません。
原因追求が難しい理由の一つにdisk読み書きの非同期性にあります。 ユーザランドでのwriteシステムコール発行から実際にdiskにデータが書き込まれてflushされ、そのデータを読み込んでチェックするまでたくさんのworkerキューを通ります。 したがってエラー検出した時点のバックトレースはほとんど役に立たないのです。 またdriver内でログを記録しようとするとそのIOが本来のwrite IOを邪魔してしまいます。
それからdriver内部で一つのデータが複数に分割されたり、その逆に複数のデータが一つにまとめられたりすることもあります。 そうなるとデータの追跡が難しくなります。 実際、writeされたデータの一部だけが壊れるという現象が発生していました。
そんな中、10月頃kernelをハングアップさせてrebootする作業をしているときにシステムをcold bootすると再現性が高くなることに気づきます(ソフトウェアrebootでは発生しない)。 このあたりでソフトのバグではなく、ハードのバグの可能性も考慮し始めました。
もちろん当初から複数の環境でテストすることでバグが再現するマシンとしないマシンがあることには気がついていたのですが、それがハードの差によるタイミングの問題なのか、ハードそのものの問題なのかの切り分けが難しかったのです。 また私たちのツールの細かいバグをいろいろ修正していたので安易に他人のせいにするわけにはいきませんでした。
原因の特定
(試行錯誤があったのですが省略)その後今度はWalB driverを用いずに、WalB driverと似たようなdisk IOを発生させるユーザランドのツールを作成します。 そしてこのツールを用いてもlogpackエラーが発生したのです。 これによりWalBのせいではないことが確定しました。心が晴れた瞬間です!!!
私たちの特殊なdriverを使わないでもバグを再現できたことでユーザランドのみで完結し、ぐっと調査しやすくなりました。 disk IOの詳細を表示できるblktraceを用いて調査を進めると、IOが発行されているのにdiskに書き込まれない証拠が見つかりました。
下記はblktraceの一部を抜粋して成形したものです。
252,7 1 12079 228.808092957 4494 Q W 3296001 + 1 [kworker/u66:21] ← logpack header submitted 8,2 1 162836 228.808094689 4494 A W 622367489 + 1 <- (252,7) 3296001 8,0 1 162837 228.808095153 4494 A W 622867201 + 1 <- (8,2) 622367489 8,0 1 162838 228.808095648 4494 Q W 622867201 + 1 [kworker/u66:21] 8,0 1 162839 228.808099628 4494 G W 622867201 + 1 [kworker/u66:21] 252,7 1 12080 228.808101183 4494 Q W 3296002 + 256 [kworker/u66:21] ← logpack IO submitted 8,2 1 162840 228.808101724 4494 A W 622367490 + 256 <- (252,7) 3296002 ... (snip) ... 8,0 1 162854 228.808198793 4494 Q W 622867459 + 256 [kworker/u66:21] 8,0 1 162855 228.808199268 4494 G W 622867459 + 256 [kworker/u66:21] 8,0 7 187897 228.808255052 4367 C W 622867202 + 256 [0] 252,7 7 19389 228.808256993 4367 C W 3296002 + 256 [0] ← logpack IO completed 8,0 7 187898 228.808260877 4367 C W 622867201 + 1 [0] 252,7 7 19390 228.808261198 4367 C W 3296001 + 1 [0] ← logpack header completed
データフォーマットの詳細は省略しますがここでは252,7はデバイス番号, 8, 2はsda2を表します。 3296001セクタ目に対して書き込みがrequestキューにsubmitされ(Q)、最後にcompleted(C)が表示されています。 つまりここでdiskへの書き込みは完了しているはずなのです。 しかしそのセクタを読むとzeroのままでデータが書き込まれていませんでした。
これによりdisk*1の不具合であることがほぼ確定です。
詳しい調査の結果、複数同時にデータ書き込みを行うと、その書き込みが完了したのに、そのデータが実は書き込まれずにロストすることがあるというRAIDコントローラの不具合だとわかりました。 信頼性が売りのRAIDコントローラでもそんな基本的なバグがあるのですね。
なお、新しいRAIDコントローラを持つサーバでチェックツールを動作させたところ、その様な不具合は再現しませんでした。
感想
ソフトのバグとハードのバグが微妙に絡んでいたため特定に時間がかかってしまいました。 今回のバグ調査は非常に長期にわたったため(もちろんこれだけをしていたわけではありませんが)、星野は精神的にかなり辛かったようです。 負けない心が大事ですね(cf. 「バグを突き止める技術」)。
今後
この調査によって様々な負荷テストが追加されて、システムの信頼性も高くなったと思われます。 現在は社内環境への導入に向けて進めているところです。
*1 ここでdiskと書いていますが、実際には10台のHDDでハードウェアRAID6を組み(+2台のホットスワップ)、その上にLVMで作成した論理ボリュームを指します。
ハードウェアRAID6を使わずにLVMだけで管理したボリュームに対しては不具合が発生しないことは確認済みです(2016/1/13追記)。
参考 : cybozu.com : お客様の大切なデータを守る4重のバックアップ